
판다스와 설레는 만남
엑셀이 답답해서 속이 터집니다!
컴공이 아닌 대학생이 가장 먼저 배우는 데이터 분석 툴은 엑셀이 아닐까 싶다. 엑셀의 그래프 기능을 통해 데이터를 다양한 방식으로 빠르게 시각화할 수 있고, 피벗 테이블 기능으로 수많은 데이터를 빠르게 군집화하고 분석할 수 있다. 무엇보다 편리한 UI 덕분에 별다른 전문 지식 없이 누구나 사용 가능하다.
하지만, 엑셀이 만능 데이터 분석 툴은 아니다. 데이터가 많아질수록, 렉이 급격히 심해지고 튕기는 현상이 많아진다. 다룰 수 있는 데이터 개수도 제한이 있는데, 한 시트마다 생성 가능한 행의 개수는 1,048,576개다. 이전에 다닌 스타트업은 AI로 영상을 분석해 데이터를 추출하는 서비스를 제공하는 곳으로, 서비스 특성상 실시간으로 엄청나게 많은 데이터가 생성된다. 모든 데이터를 엑셀로 뜯어보는 건 당연히 무리였다. 엑셀이 버벅거려 답답해하는 나에게 개발자가 찾아와 말했다.
명성님, 이참에 판다스 공부해보는 건 어떠세요?

많은 데이터를 엑셀로 처리하기 답답하다면, 판다스가 하나의 수단이 될 수 있다. 판다스는 파이썬의 데이터 처리 및 분석 라이브러리로, 많은 양의 데이터를 단기간 내 처리해준다. 데이터셋 내에서 특정 조건을 입력해 일부 데이터만 추출하거나, 특정 칼럼이나 데이터만 함수를 적용하는 등 많은 것을 할 수 있다. 엑셀에 익숙한 사람이라면 쉽게 배울 수 있는데, 약간 엑셀을 코딩으로 다루는 느낌이다.

의사결정의 품격, 데이터 시각화
데이터의 흐름을 보는 자!
데이터 시각화가 중요한 이유는 무엇일까? 모든 의사결정은 데이터에 기반해야 하는데, 그렇지 않으면 개인의 경험이나 주관적 판단에 의해 잘못된 해석을 할 수도 있다. 그렇다고 무작정 개별 데이터를 하나하나 보는 게 의사결정에 큰 도움이 되는 것도 아니다.
의사결정을 위한 데이터 인사이트를 얻으려면, 수많은 데이터 사이에 존재하는 흐름을 찾아야 한다. 이 흐름은 개별 데이터를 하나하나 보면 볼 수 없고, 모든 데이터를 전체적으로 봐야지만 찾을 수 있는데 이를 가능케 하는 게 ‘데이터 시각화’다.
판다스와 함께 자주 쓰이는 파이썬의 데이터 시각화 라이브러리로 시본(Seaborn)이 있다. 판다스와 시본, 2가지를 공부한다면 엄청난 수의 데이터를 판다스로 처리 및 분석하고, 시본으로 시각화해서 데이터의 흐름을 파악할 수 있다. 만약 판다스와 시본, 둘 다 공부하기 힘들다면 그냥 시본만 공부해도 큰 도움이 될 수 있다. 사실 판다스면 몰라도, 시본은 함수명도 직관적이고 코드도 어렵지 않아서 누구나 쉽게 배울 수 있다.
누구나 이 정도로 데이터 시각화를 할 수 있다고?
0. 변수 개념
시본의 시각화 함수를 알아보기 전에 ‘범주형 변수(categorical variable)’와 ‘연속형 변수(continuous variable)’ 개념을 먼저 뜯어보자! 정량 변수는 특성에 의해 크게 ‘범주형 변수’와 ‘연속형 변수’로 구분된다. 범주형 변수는 측정 대상들이 서로 떨어진 값을 갖고 있어서 명확하게 구분되는 변수인데, 성별(남성 / 여성), 연령대(10대 / 20대 / 30대 / 40대…) 등이 여기에 속한다. 반대로, 연속형 변수는 측정 대상들이 서로 연속된 값을 갖고 있다. 예를 들어, 키(150cm ~ 200cm), 온도(0’C~100’C), 나이 (0살 ~ 100살) 등이 있다. 이 두 변수의 특성을 구분할 줄 안다면, 시본을 더 익숙하게 사용할 수 있다.
범주형 변수와 연속형 변수를 이해했으니, 이제 시본에서 제공하는 시각화 함수를 느껴볼 차례다. 시본에서 제공하는 시각화 함수 중에서 가장 자주 쓰이는 몇 가지를 가져왔으니, 편한 마음으로 “아 시본을 공부하면 이 정도 수준으로 시각화가 가능하구나?” 정도만 느끼면서 구경하자.
- 특정 변수의 빈도, 횟수를 확인 -> countplot, distplot
- 범주형 변수와 연속형 변수의 관계 확인 -> boxplot, violinplot, stripplot.
- 연속형 변수와 연속형 변수의 관계 확인 -> regplot, kdeplot

1. 특정 변수의 빈도, 횟수 확인하기
- countplot 함수
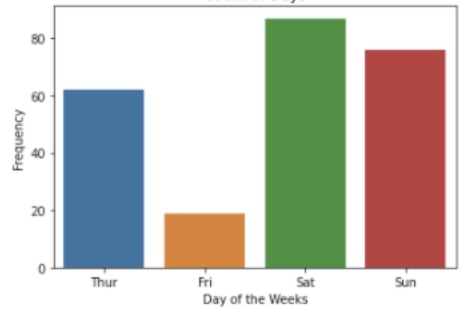
countplot 함수는 범주형 변수의 빈도, 횟수 등을 막대그래프로 보여주는 함수다. 아래 그림처럼, 각각의 범주형 변수가 데이터에서 몇 개가 있는지 막대로 보여준다. 아래 차트를 보면, 각 요일의 응답 수를 확인할 수 있다. 여기서 요일인 목, 금, 토, 일이 범주형 변수다.
- distplot 함수
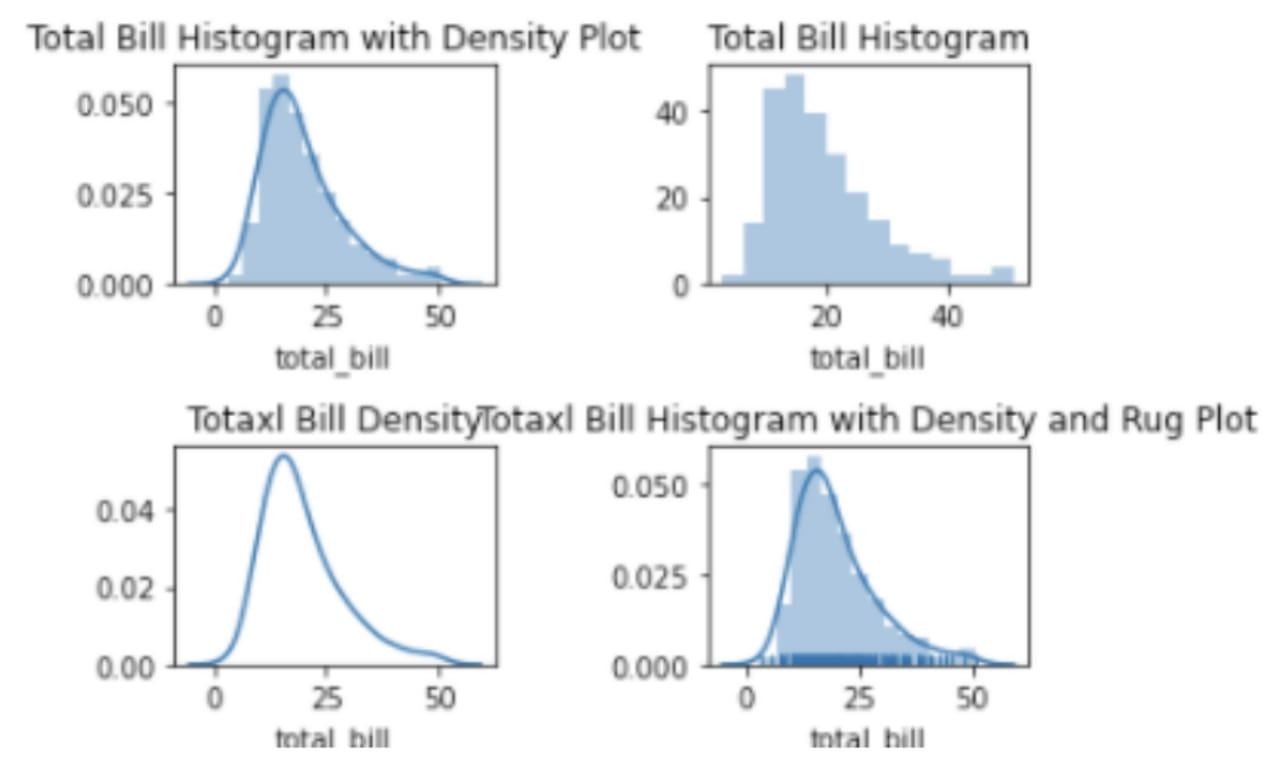
연속형 변수의 빈도, 횟수 등을 확인하려면 distplot을 사용하면 된다. distplot은 연속된 각 변수의 개수를 히스토그램으로 보여준다. 별도 설정을 통해 커널 밀도(kde)를 그릴 수 있는데, ‘커널 밀도’는 앞선 히스토그램을 기반으로 만든 확률 함수다. 즉, 특정 데이터를 랜덤하게 뽑았을 때 해당 값이 있을 확률을 뜻하는데, 그냥 편하게 추세선으로 생각하자!
2. 범주형 변수와 연속형 변수의 관계 보기
- boxplot 함수
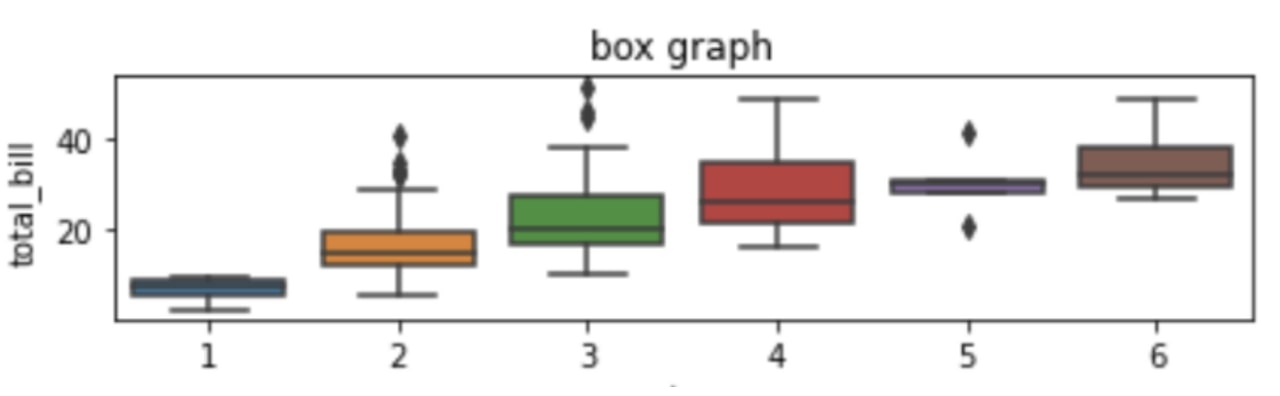
boxplot은 범주형 변수와 연속형 변수 사이의 관계를 보여준다. 이때, 연속형 변수에서 최솟값, 1분위 수, 중간값, 3분위 수, 최댓값, 이상치 등의 다양한 통계량을 함께 보여준다.
- violinplot 함수
위의 boxplot은 다양한 통계 수치를 확인하기 위해 자주 사용된다. 하지만, 특정 분위 수나 중간값을 보여줄 뿐, 데이터 분산을 정확하게 보여주지 않는다. 이때 violnplot 함수를 사용하는데, 통계량을 다루지 않는 대신에 커널 밀도를 통해 데이터 분산을 확인할 수 있다.
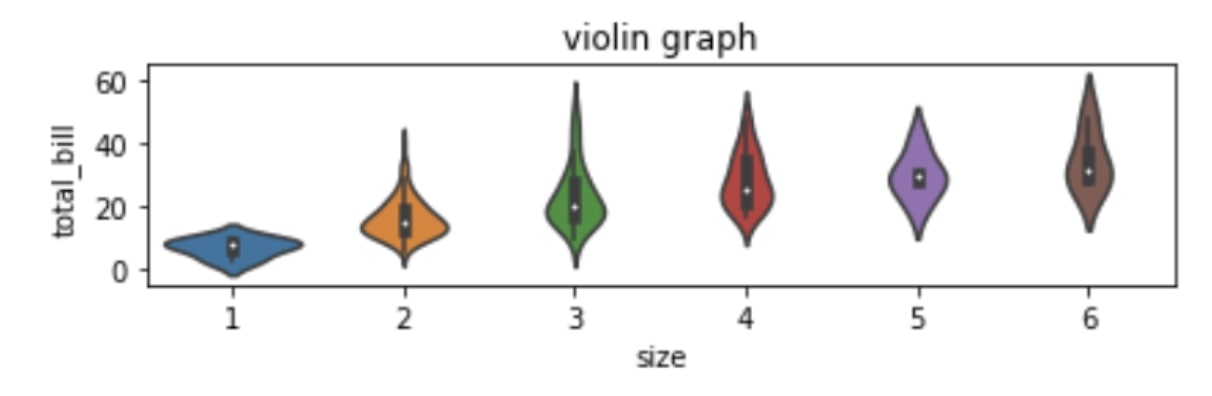
- stripplot 함수
violinplot, boxplot 함수는 개별 관측치를 종합해 특정 형태로 보여준다. 만약 개별 관측치 하나하나를 보고 싶다면, stripplot 함수를 사용하면 된다.
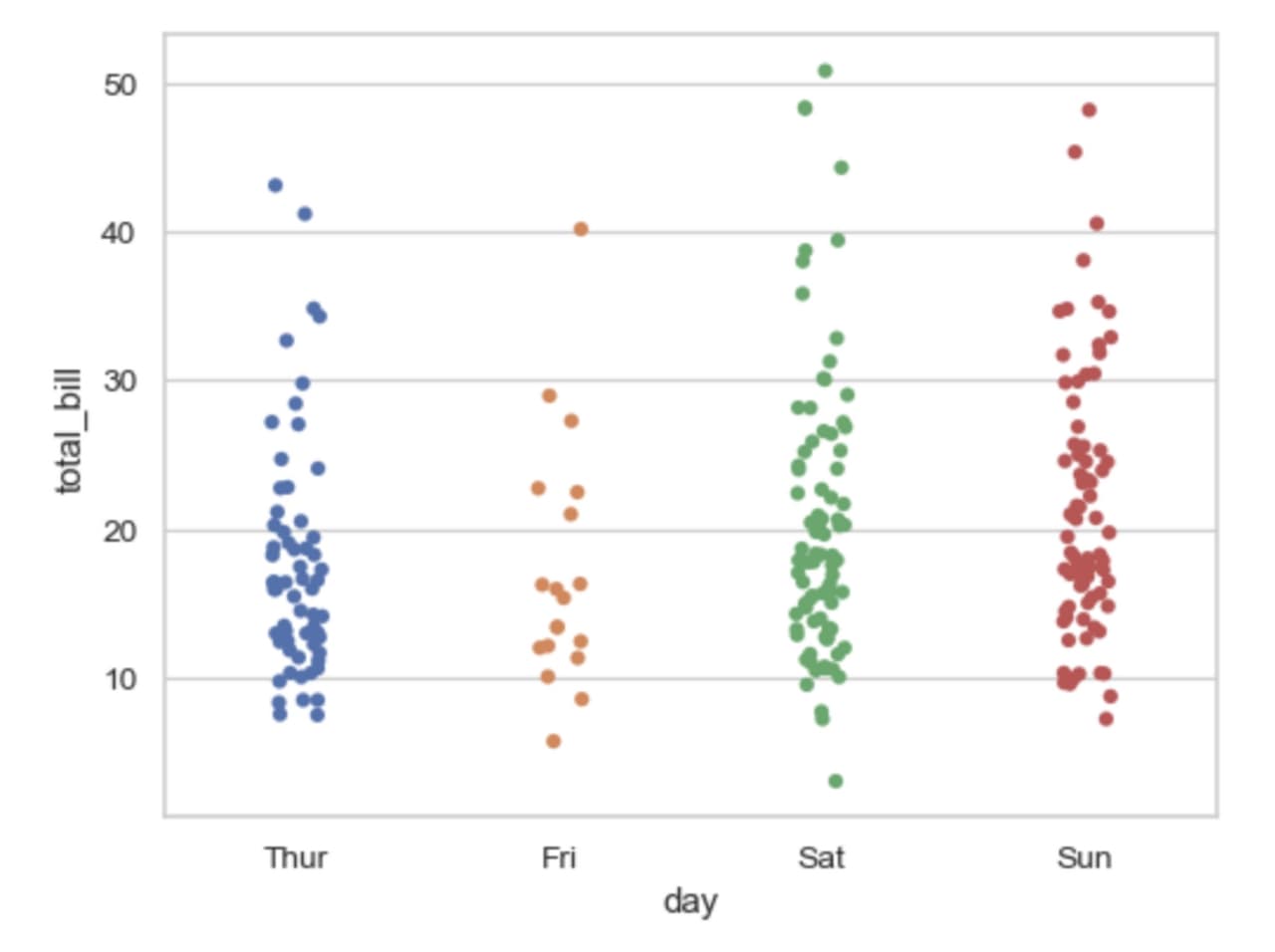
3. 연속형 변수와 연속형 변수의 관계 보기
- regplot 함수
서로 다른 연속형 변수 사이의 관계가 어떻게 됐는지를 알고 싶을 때, 산점도를 그리는 regplot 함수를 사용한다. 두 변 사이에 회귀선을 보여줘서 상관관계를 어느 정도 예측할 수 있고, 데이터가 많아서 겹치는 점이 많은 경우에 투명도를 설정해서 각 구간마다 데이터가 얼마나 몰려있는지 알아낼 수 있다.
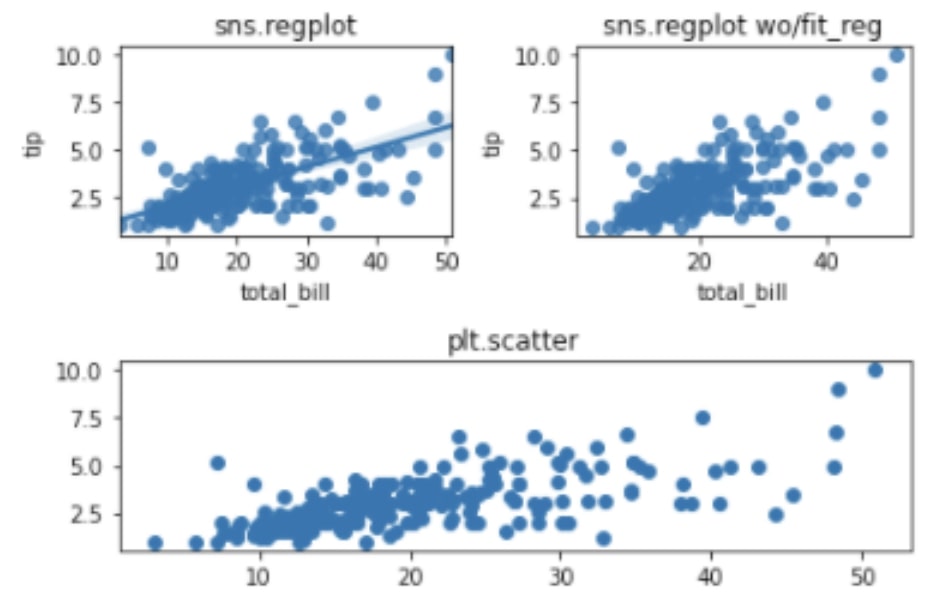
- kdeplot 함수
두 연속형 변수 사이의 관계를 보여준다는 점에서 regplot과 비슷하지만, 보여주는 방식이 다르다. regplot은 각 관측치를 모두 점으로 보여준 것에 반해, kedplot은 이차원 밀집도로 보여준다.
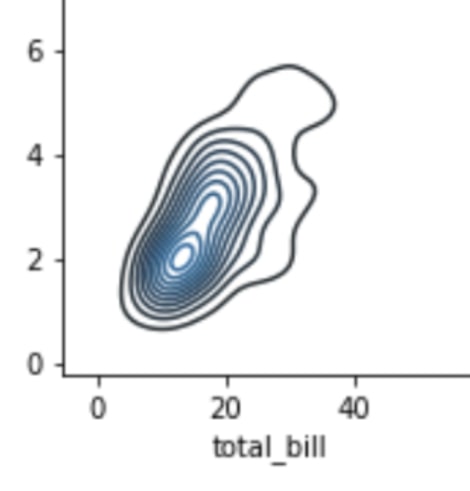
데이터 시각화로 진짜 문제 찾기
1. 창업 팀 사례
얼마 전 창업 팀에서 PSF(Problem Solutin Fit)을 찾기 위한 실험을 진행했다. 당시 여러 문제 중에서 고객이 가장 크게 느끼는 문제가 무엇인지 알아내기 위해 설문 조사를 진행했고, 수집한 데이터를 분석해 팀의 방향을 설정했었다. 이 사례를 짧게 공유해보고자 한다.
문제 순위를 매겨보자!
고객의 문제를 찾는 방법 중에 CPSR이란 방법이 있다. 고객에게 하나의 문제가 아니라, 여러 문제를 보여주고 순위를 매기는 방식이다. 하나의 문제만 물어본다면, 고객은 그 문제 외의 것은 모두 잊어버리고 그 문제만 집중하는데, CPSR은 이런 상황을 방지한다. 이 점에 착안해 1개의 문제 가설을 검증하기보다 우선순위가 높다고 판단한 4개의 문제를 고객에게 모두 보여주고, 이 중에서 어떤 게 가장 큰 페인 포인트인지 알아내는 실험을 진행했다. 각 문제마다 고객에게 불편도를 묻는 여러 문항으로 설문지를 구성하고, 이를 관련 커뮤니티에 배포해 데이터를 수집했다.
판다스로 데이터 처리
이렇게 수집한 데이터를 csv로 추출하고, Pandas를 이용해 데이터를 시각화하기 전에 전처리했다. 각 문제의 불편도를 측정하기 위한 여러 문항에 가중치를 적용해 점수로 환산했고, 아래와 같이 process, menu, pay, coupon 칼럼을 생성해 입력했다. 즉, 각 칼럼은 이번에 순위를 매기고자 한 4가지 문제와 불편함 점수를 뜻한다.
아래 수치는 설문지 응답을 기반으로, 각 문제에 느낀 불편함을 정량적으로 환산한 것이다. age, gender 칼럼은 인구통계학 정보를 보여준다. seaborn로 데이터를 시각화하려면, str(남성, 여성, 20-23) 타입이 아니라 int 타입으로 바꿔주는 게 유리하다.
어떤 문제가 가장 큰 문제일까?
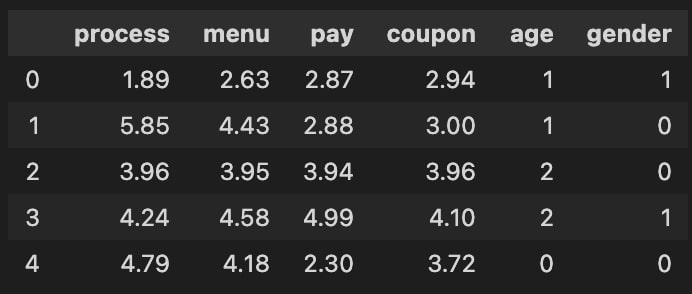
연속형 변수의 빈도, 분포도를 알고 싶다면, seaborn의 distplot을 활용하면 좋다. 아래 그래프는 distplot으로 구현된 커널 밀도 그래프이다. 봉오리가 x축의 오른쪽으로 갈수록, 문제가 불편하다고 말하는 사람이 많음을 뜻한다.
해당 그래프를 보면, Pay(초록)의 봉오리가 가장 왼쪽에 있고, Menu(주황)의 봉오리가 가장 오른쪽에 있음을 볼 수 있다. 즉, 데이터를 보면 Menu 문제에서 가장 큰 불편함을 느끼고 있다.
fig, ax = plt.subplots(1,1, figsize= (20,10))
sns.distplot(df_pt[‘process’], hist = False, label = “Process”)
sns.distplot(df_pt[‘menu’], hist = False, label = “Menu”)
sns.distplot(df_pt[‘pay’], hist = False, label = “pay”)
sns.distplot(df_pt[‘coupon’], hist = False, label = “coupon”)
plt.grid(True)
plt.legend()
plt.show()
각 성별, 연령대에서는 어떨까?
이 그래프를 좀 더 딥 다이빙해보자! 해당 그래프는 모든 성별, 연령대의 데이터로 그려본 커널 밀도니, 다음과 같은 질문을 던질 수 있다.
“고객이 가장 불편하다고 말한 ‘Menu 문제’가 알고 보니, 특정 성별, 연령대에만 한정적인 건 아닐까?”
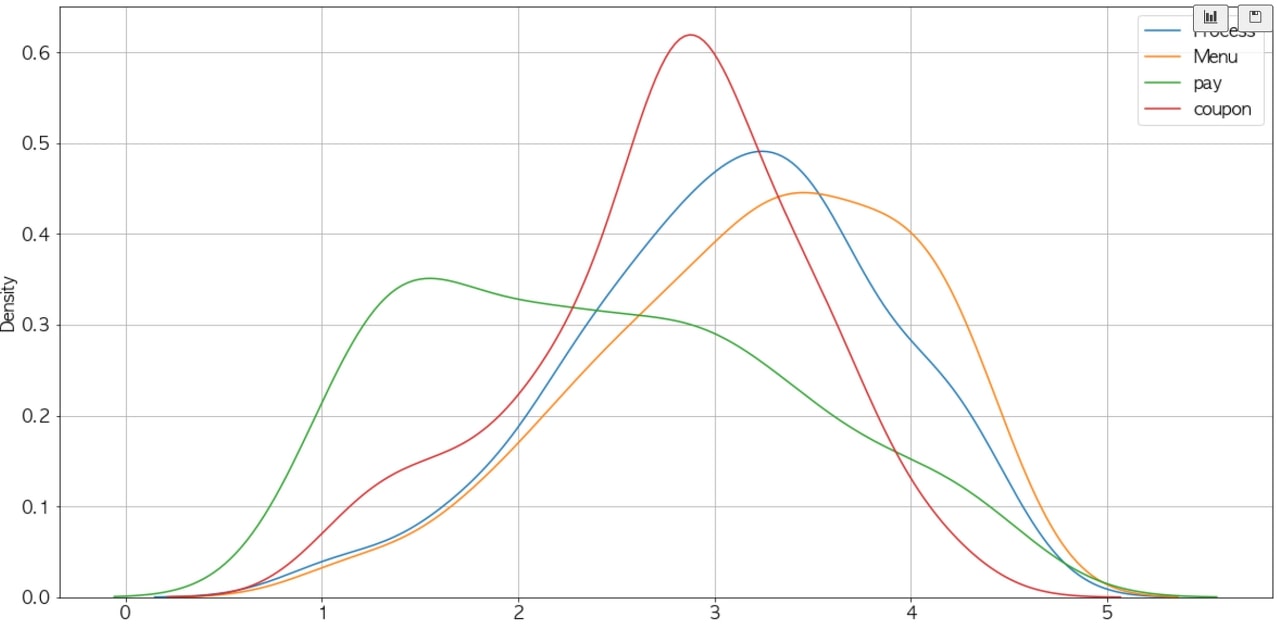
이제 각 성별, 연령대 세그먼트로 불편함을 확인하기 위해 violinplot과 stripplot을 사용했다. 두 함수는 범주형 변수(성별, 연령대)와 연속형 변수(불편도 점수) 사이의 관계를 알아낼 때 사용하면 좋다. violinplot은 각 데이터가 어떤 구간에 주로 분포하는지 커널 밀도로 보여주고, stripplot은 개별 데이터가 어디에 위치하는지를 보여준다. 따라서, 이 둘을 하나의 그래프에 함께 그리면 더 보기 편하다.
결과 그래프를 확인해보면, 24~26세 여성이 메뉴의 불편함을 가장 크게 느끼고 있음을 알 수 있다. 이제 ‘Menu 문제’를 가장 크게 불편하다고 느끼는 건 24~26세 여성임을 알아냈다.
fig, ax = plt.subplots(1,1, figsize= (10, 5))
sns.violinplot(x = ‘age’, y = ‘menu’, data = df_pt, hue = ‘gender’, split = True, orient=’v’, legend =[‘여성’, ‘남성’])
sns.stripplot(x = ‘age’, y = ‘menu’, data = df_pt, hue = ‘gender’, size = 5)
ax.set_xticklabels([’20세 미만’, ’20 – 23′, ’24 – 26′, ’27 이상’]) plt.grid(True)
plt.legend([‘여성’, ‘남성’])
plt.show()
다른 변수 사이의 상관관계는 없을까?
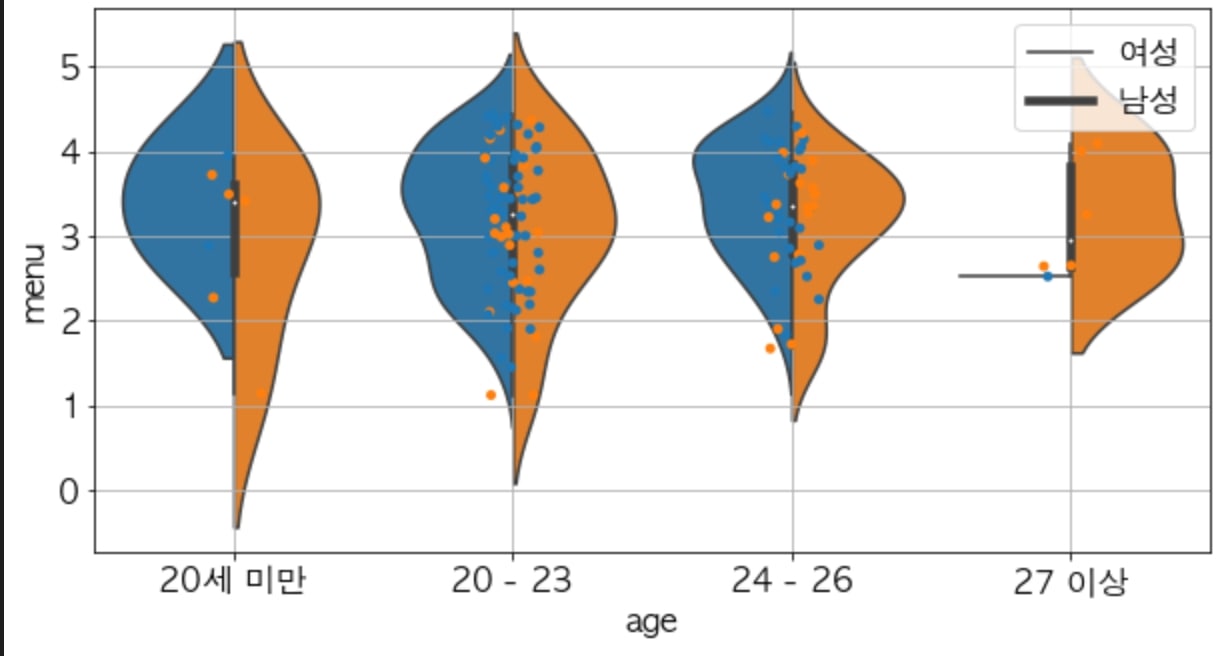
여기서 좀 더 깊이 들어가 보자. 24~26세 여성이 답한 응답이 사실 다른 문제로부터 어떤 영향을 받은 건 아닐까? 서로 다른 연속형 변수 사이의 상관관계를 보고 싶다면 regplot을 활용하면 좋다. regplot은 두 변수 사이의 데이터 위치를 산점도로 보여주고, 회귀선을 그려서 변수 사이의 상관관계를 보여준다.
아래의 각 그래프는 Menu 문제와 각각 Process, Pay, Coupon 문제 사이의 상관성을 회귀선으로 보여준다. 회귀선을 보면, 메뉴와 다른 요소 사이의 상관성은 크게 없음을 알 수 있다.
df_target = df_pt.groupby([‘age’, ‘gender’]).get_group((2,0))
fig, axes = plt.subplots(1,3, figsize= (30,8))
sns.regplot(x = ‘menu’, y = ‘process’, data = df_target, ax= axes[0])
sns.regplot(x = ‘menu’, y = ‘pay’, data = df_target, ax= axes[1])
sns.regplot(x = ‘menu’, y = ‘coupon’, data = df_target, ax= axes[2])
for n in range(0,3):
axes[n].grid(True)
axes[n].set_ylim([1, 5])
plt.show()
세 그래프를 하나의 그래프에 그려보고 비교할 수도 있다.
df_target = df_pt.groupby([‘age’, ‘gender’]).get_group((2,0))
fig, axe = plt.subplots(1,1, figsize= (10,10))
sns.regplot(x = ‘menu’, y = ‘process’, data = df_target, label = ‘process’)
sns.regplot(x = ‘menu’, y = ‘pay’, data = df_target, label = ‘pay’)
sns.regplot(x = ‘menu’, y = ‘coupon’, data = df_target, label = ‘coupon’)
plt.legend()
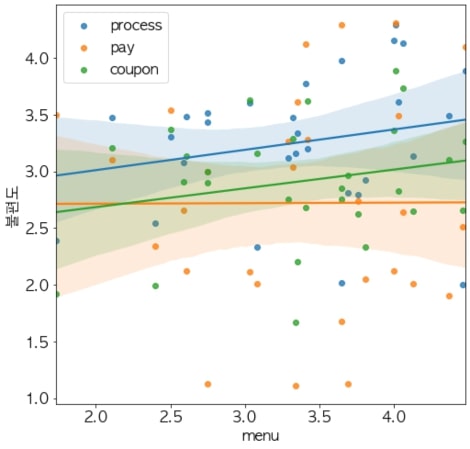
2. 100% 정확하지 않아도 괜찮다!
사실 이 데이터가 더 신뢰성을 얻기 위해선 더 많은 데이터가 필요하다. 하지만, 스타트업에서 필요한 건 빠른 속도다. 따라서, 100% 정확한 정보를 얻을 때까지 기다리는 것보다, 어느 정도의 정확성을 가진 정보를 갖고 바로 다음 액션을 하는 게 더 효과적이다.
팀에서 ‘Menu 문제’를 24-26세 여성 고객의 핵심 문제로 설정하고, 넥스트 액션을 이에 맞춰서 진행했다. 만약, 데이터를 분석하지 않았다면, ‘process’나 ‘coupon’을 핵심 문제로 설정했을 수도 있다. 해당 그래프의 일부는 엑셀로도 충분히 구현할 수 있지만, 좀 더 데이터 기반의 의사결정 능력을 키우기 위해 데이터 분석 코딩 공부를 해보는 건 어떨까?
그래서 어떻게 공부하지?
판다스와 시본은 혼자서 독학으로 공부했다. 처음에 책을 통해 입문헀고, 이후 무료 강의 영상을 보면서 기본기를 다졌다. 사실 데이터 애널리티스트를 꿈꾸는 게 아니라면, 이 정도만 해도 충분하지 않을까? (물론 주관적인 뇌피셜이다)
개발자가 『 Do it! 데이터 분석을 위한 판다스 입문』을 빌려줘서 판다스와 시본 기본기를 뗐다. 판다스 입문이지만, 데이터 시각화를 위해 시본을 다루는 챕터가 있어서 좋았다. 이어서 김문과님이 seaborn 패키지 번역본을 올리셨다. 한땀한땀 번역하셨다고 했는데 존경스러울 정도다…! 시본만 공부해보고 싶다면, 이 번역본을 한 번 봐보자!
글을 읽는 게 싫다면, 유튜버 ‘나도코딩’님의 시각화 강의 영상을 참고해보자! 강의도 엄청 친절하고 기초부터 차근차근 다뤄주셔서, 글을 읽으면 잠이 오는 분들에게 좋을 듯하다.
원문: FameLee의 브런치
이 필자의 다른 글 보기