
우아한 백조의 물밑 노가다는 눈에 잘 띄지 않는다. 그래서인지 데이터 분석, 데이터 시각화라는 용어가 꽤 흔해졌음에도 데이터 노가다의 현실 역시 잘 알려지지 않는 듯하다.
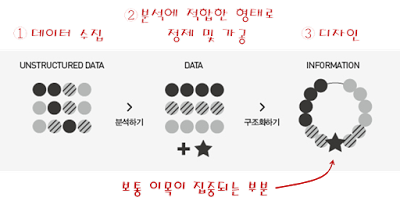
이 글, 「보이는 작업량은 빙산의 일각」은 전체 데이터 시각화 과정 중 디자인 노가다의 어려움을 잘 설명한 글이다. 이왕 알아본 김에 데이터 수집 및 정제 과정의 노가다에 대해서도 알아보자.
이런 데이터 분석은 어떻게 하는 걸까?
당연히 일단 데이터가 있어야 한다.

SBS 뉴스 데이터를 수집해보자. 구글의 ‘intext:박근혜 site:news.sbs.co.kr’ 검색 옵션은 news.sbs.co.kr 웹 사이트에서 본문에 ‘박근혜’가 포함된 문서만을 검색해준다.
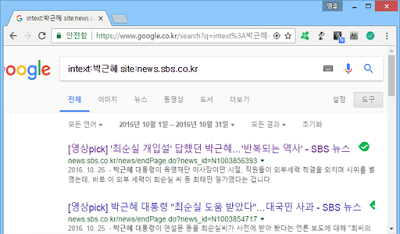
그런데 데이터를 어떻게 가져오지? 일일이 복사 & 붙여넣기?
‘마부작침(도끼를 갈아서 바늘을 만든다)’이라고 끈기를 가지면 못 이룰 일은 없겠지만, 바야흐로 굴도 기계가 까주는 세상. 데이터를 긁어오는 기계를 만들어보자.

기계가 되어줄 도구는 인터넷 주소를 이용해서 데이터를 송수신할 수 있는 cURL. 다음 슬라이드는 cURL을 이용한 데이터 수집 과정. (재미는 없음)
7단계의 공정을 거쳐 약 20만 줄의 데이터를 수집했다. 내 입장에서 원본 데이터는 보통 이런 식으로 생겼으며, 불필요한 데이터 제거, 분석하기 쉬운 형태로의 구조 변환 등이 필요한, 불완전한 데이터이기 때문에 원시 데이터라고도 한다.
개인적으로 원시 데이터를 분석하기 쉬운 형태, 컴퓨터가 이해하기 쉬운 형태로 바꿀 때, 텍스트 에디터인 VIM이라는 도구를 애용한다. 보통 우리가 분석하려는 대부분의 데이터는 텍스트이기 때문. 다음은 15단계의 공정 끝에 정제가 끝난 데이터.
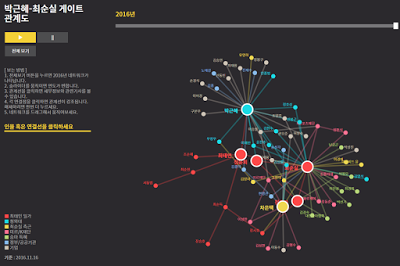
내친김에 디자인도 해보자. 다음은 7단계 공정 끝에 탄생한 디자인 결과물. ‘Gephi’라는 오픈소스 데이터 시각화 도구를 사용했다. SBS 사례와는 비교 불가.^^;
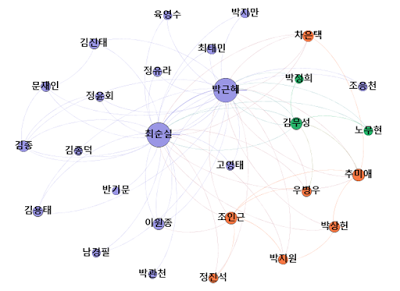
데이터 정제 및 디자인 과정은 다음 슬라이드 참고.
cURL, VIM(과 정규표현식), 엑셀, Gephi 4개의 도구를 이용한, 데이터 수집부터 디자인까지 29단계의 데이터 분석(이라고 쓰고, 노가다라 읽는) 과정을 살펴봤다. 디자인 과정이 간단한 이유는 일단 디자인은 잘 모르기도 하고, 보통은 내 군생활이 제일 빡센 법이니깐.

세상 만사는 노가다
얼마 전 모 신문사로부터 박근혜 지지자들이 박근혜 사저에 남긴 포스트잇 메시지에 대한 분석을 의뢰받았었다. 어떻게 수집했냐고 물었더니 600여 개 정도의 포스트잇 메시지를 전부 옮겨 적었다고. ㅡㅡ;
『신호와 소음』의 저자 네이트 실버는 이런 얘기를 했다
데이터는 어느 날 갑자기 태어나는 것이 아닙니다. 우리는 깔끔하게 정리된 절대적인 데이터를 엑셀 시트로 분석할 수 있다고 착각하곤 합니다. 그러나 현실 세계에서 그런 일은 없습니다. 데이터는 결국 사람에 의해 수집됩니다.
빅데이터, 인공지능이 유행이지만 컴퓨터를 부려먹으려면 아직까지는 사람의 노가다가 필요한 세상이다.

원문: 케세라세라