
필자가 어디서 ‘데이터 과학자’라고 하면 보통 ‘아, 빅데이터 하시는군요’ 라고 하시는 분들이 많다. 하지만 필자가 누누이 밝혔듯이 데이터는 문제 해결의 수단이고, 빅데이터를 꼭 써야 문제가 풀리는 것은 아니다. 필자는 빅데이터보다 주변의 문제를 끊임없이 데이터로 푸는 ‘생활 데이터’가 필요하다고 믿는다.
생활 데이터 사례: 당뇨병 관리 & 치킨집 수요 예측
우선 생활 데이터를 사례로 알아보자.
한국 네스프레소(Nepresso)의 디지털 어퀴지션 매니저로 일하는 서영부님에게는 최근 고민거리가 생겼다. 장모님께서 당뇨병 진단을 받으신 것이다. 아버님께서 10년 넘게 당뇨 증상이 있으셨던 터라 당뇨병 환자에게 필수적인 혈당 관리의 번거로움을 누구보다도 잘 아는 그였다.
실제로 장모님께서는 새로운 식이요법에 적응하느라, 혈당 측정을 하시느라 여러 가지 어려움을 겪고 계셨다. 공복 시 혈당은 120 이하, 식후 혈당은 160 이하를 유지한다는 목표를 세우고 아침 공복 1번, 식후 3번 측정의 빈도로 측정을 시작하셨지만 이를 꾸준히 기록하는 것을 힘들어하셨다.
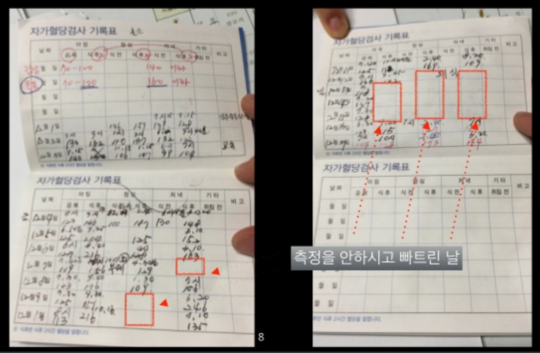
평소 업무상 데이터를 늘 활용하는 서영부님은 장모님께 혈당관리를 위한 데이터 사용법을 가르쳐드렸다. 종이에 입력하시던 혈당 데이터를 엑셀에 옮겨 추이를 보여드리고, 추가로 데이터를 넣으시면 그래프가 그려지도록 만들어드린 것이다. 또한, 혈당 관리를 위해서는 어느 기준점 이하로 그래프가 내려가야 한다는 점을 이해시켜드렸다.
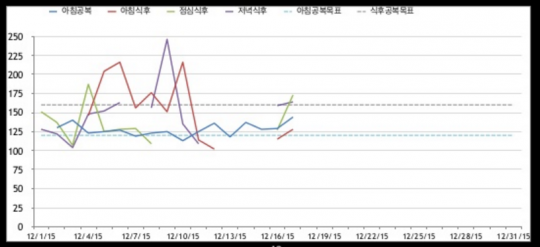
이를 통해 장모님께서는 측정하는 숫자와 목표 간의 관계를 이해하실 수 있었다. 이와 함께 서영부님은 장모님께서 혈당관리에 필수적인 운동량을 채우실 수 있도록 미 밴드도 드렸다. 단순히 밴드를 드린 게 아니라 운동량의 기준을 설정하여 운동량이 부족한 날은 더하시고, 많은 날은 쉬시도록 말씀을 드렸다. 이런 사위의 정성에 장모님이 감동하신 것은 물론이다.
이상은 작년 12월 필자가 주최한 ‘생활데이터’ 모임에서 서영부님께서 직접 발표하신 내용이다. 서영부님은 본인이 의사 거나 의학 데이터를 다루어 보신 것은 아니지만, 간단한 도구를 사용하여 주어진 데이터를 시각적으로 이해하고, 운동량을 정확히 측정하도록 장모님을 도와드린 것이다. 위 사례에서는 엑셀을 사용했지만, 필자의 지난 글에서는 종이와 펜만으로 15년간 당뇨병을 이겨낸 사례를 소개하기도 했다.
간단한 데이터 활용으로 비즈니스에 큰 변화를 가져온 예도 있다. 작년 통계청에서 주최한 통계 활용 수기 공모에서 최우수상을 차지한 통계로 튀기는 치킨은 치킨집을 하는 아버지를 돕기 위해 매일 매일의 계육 수요를 예측하는 모델을 만들어 활용했던 대학생 허성일 님의 이야기다. 제품의 품질과 비용 절감을 위해 필수적인 수요 예측의 문제를 계절, 날씨, 이벤트와 같은 단순한 속성을 바탕으로 예측해낸 것이다.
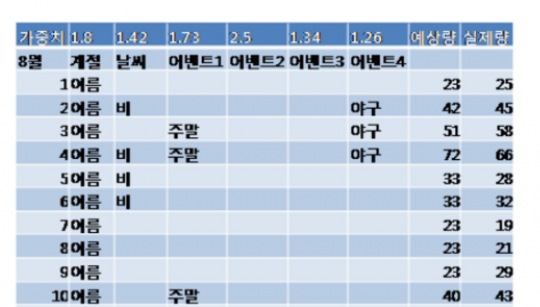
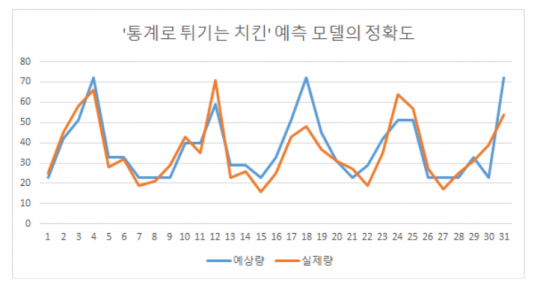
예측 모델이라지만 사실 위 테이블에서 보듯 몇 개의 변수에 가중치를 주어 결합하는 방정식이니 복잡한 통계 기법을 사용한 것은 아니다. 하지만 위 모델의 예상량과 실제량을 비교한 아래 그래프를 보면 상당한 정확도를 자랑함을 알 수 있다. 허성일 씨가 이 예측모델로 아버님의 사람을 듬뿍 받은 것은 물론이다.
생활 데이터를 실천하는 사람들: Quantified Self
위 사례의 주인공들에게는 자기 주변의 문제에서 출발하여, 비교적 간단한 데이터와 방법으로 문제에 접근하였다는 공통점이 있다. 데이터라면 흔히 대형 컴퓨터나 복잡한 수식을 떠올리지만, 이들은 데이터를 두려워하는 대신 자신의 문제를 해결해주는 수단으로 적극 활용한 것이다. 필자는 이처럼 데이터를 자신의 문제를 푸는 수단으로 적극적으로 활용하는 태도를 ‘데이터 생활화’ 혹은 ‘생활 데이터’라고 부르고 싶다.
이처럼 데이터를 적극적으로 활용하는 개인의 이야기가 약간 낯설게 느껴질지도 모르겠다. 하지만 정보기술의 발전에 따라 최근 들어 개인이 자신의 삶과 업무에서 데이터를 수집하여 활용하려는 움직임이 전 세계적으로 확산되고 있다. 그리고 이 트렌드의 중심에는 앞서 소개한 Quantified Self라는 (의미: 계량화된 자신, 이하 QS) 이름의 커뮤니티가 자리하고 있다.
QS는 말하자면 자기 주변의 문제를 직접 데이터로 해결하는 생활 데이터를 실천하는 개인들의 커뮤니티로 2007년 시작된 이래 현재 약 34개국에 100개가 넘는 지역별 그룹을 가진 단체로 성장해왔으며, 2011년부터는 매년 미국과 유럽에서 국제적인 규모의 콘퍼런스가 개최되고 있다. 이는 생활 데이터의 활용에 대한 폭발적인 관심을 대변한다. 필자는 꾸준히 QS 모임에 참여하고 있으며, 필자의 개인 행복도 측정 관련 발표는 시애틀 타임즈에도 소개되기도 했다.
그럼 QS커뮤니티의 사람들은 어떤 유형의 데이터를 모으는 것일까? 이를 살펴보면 사람들이 주로 모으는 가장 흔한 데이터는 활동량, 음식, 몸무게, 수면 및 감정 데이터이다. 자신의 웰빙과 직접 관련된 데이터를 주로 모으는 것을 알 수 있다. 하지만 사람들은 이외에도 인지 기능, 혈당량, 위치, 심박 수, 스트레스, 생산성 등 굉장히 다양한 종류의 데이터를 모으고 있다. 자세한 목록은 QS 웹사이트의 가이드를 참조하자.
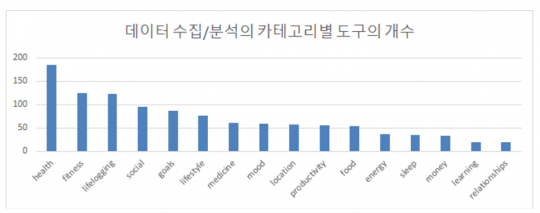
하지만 이들은 대부분 데이터 과학자가 아닌 평범한 사람에 불과했다. 그렇다면 이들은 어떻게 이런 분석을 수행하고 있을까? 최근 연구에서는 QS 커뮤니티 회원들이 자료 수집 및 분석에 주로 사용되는 도구의 분포를 소개하고 있다. 연구 결과를 보면 엑셀 등의 단순한 도구를 사용하는 사람들이 절반 가까운 44%를 차지하고 있다. 데이터로 자기 주변의 문제를 푸는데 대단한 도구가 필요하지는 않다는 결론을 내릴 수 있다.
데이터 과학 입문의 지름길: 생활 데이터
필자는 데이터 과학을 처음 공부하려는 사람들에게도 여러 이유에서 생활 데이터를 꼭 권한다. 우선 자신의 삶과 업무에 관련된 문제들을 푸는 것은 낯선 누군가의 문제를 푸는 것보다 흥미로운 일이다. 만약 데이터를 통해 나를 괴롭히는 지긋지긋한 건강 문제에서 벗어날 수 있다면? 혹은 지금 보다 업무의 생산성을 획기적으로 높일 수 있다면? 데이터 과학을 공부하기 위해서가 아니라도 충분히 동기부여가 된다.
또한, 자기 자신의 문제를 푼다면 그 문제의 핵심은 무엇인지, 그리고 어떤 데이터를 모아야 할지도 스스로 알 수 있다. 물론 도출한 해결책에 대한 평가도 스스로 내릴 수 있다. 즉 스스로 문제 정의부터 해결책 도출에 이르기까지 데이터 과학의 전 과정을 진행해볼 수 있다. 이런 경험은 앞으로 여러 사람과 좀 더 복잡하고 규모가 큰 문제를 해결할 때 큰 도움이 된다.
마지막으로 생활 데이터는 그 특성상 크기도 작고, 관련된 문제들도 단순하다. 덩치 큰 도구나 어려운 분석 기법을 적용하지 않고도 결론에 도달할 수 있다. 이런 경험을 통해 데이터에서 가치를 끌어내는 과정이 꼭 복잡하고 어려울 필요가 없다는 점을 깨닫게 될 것이다. 이처럼 주변의 현상을 데이터 관점에서 바라보는 훈련을 통해서 데이터 문제를 발견하는 시각을 기를 수 있다.
이처럼 자신의 주변에서 흥미로운 문제를 발견하고, 이를 해결해나가는 과정을 통해 데이터 과학을 공부하다 보면 어느새 데이터 과학자의 태도와 소양을 갖춘 자신을 발견하게 될 것이다. 필자가 2002년 데이터 과학이라고 부를만한 활동을 시작하게 된 것도 주변의 다양한 데이터를 모아서 분석하면서부터다. 또한 전희원 님, 권정민 님과 같은 잘 알려진 데이터 과학자들도 자기 주변의 데이터 활용 사례를 공유하고 있다.
집밥을 사랑하는 당신, 생활 데이터를 시작하라!
최근 들어 백종원 씨 등의 영향으로 집밥 열풍이 불고 있다. 집밥의 장점은 원하는 음식을 자기가 구입한 재료로 자신의 입맛에 맞게 조리해 먹을 수 있다는 점이다. 자신의 힘으로 해 먹으니 외식보다 저렴하고 안전하게 한 끼를 해결할 수 있다. 또한, 외식과 달리 집밥을 습관화하면 요리 실력이 늘어 더 적은 노력으로 더 맛있는 음식을 해먹을 수 있을 것이다.

필자는 생활 데이터를 집밥에 비유하고 싶다. 우리는 보통 다른 사람이 모으고 분석한 결과를 사용하거나, 데이터 업무를 전문가에게 맡겨야 한다고 생각한다. 하지만, 글의 서두에서 소개한 사례에서 볼 수 있듯이 데이터로 주변의 문제를 해결하는 일이 꼭 거창하고 복잡할 필요는 없다. 그리고 앞서 소개한 Quantified Self 커뮤니티와 같이 실제로 스스로 하는 데이터 수집과 분석이 글로벌 트렌드로 자리 잡고 있다.
집밥과 마찬가지로 생활 데이터의 장점은 지금 나에게 필요한 문제를 나에게 맞는 방식으로 해결할 수 있다는 점이다. 내가 수집한 데이터에서 직접 내린 결론이므로 어딘가에서 읽은 지식보다 나에게 훨씬 적합한 결론에 도달할 수 있다. 또한 다른 사람에게 맡길 필요가 없으므로 시간과 비용이 절약되는 것은 물론이다. 특히 21세기의 석유라고 불리는 데이터를 자신의 핵심 경쟁력으로 삼고 싶은 사람이라면 생활 데이터를 당장 시작해야 할 것이다.
생활 데이터를 시작하는 사람들: ‘생활데이터’ 그룹
그럼 어디서 생활 데이터를 시작할 수 있을까? 우선 데이터 과학에 대한 필자의 다양한 글을 참고하고, 필자가 작년 말 시작한 페이스북 생활데이터 그룹에서 생활 데이터를 시작하는 데 필요한 다양한 조언을 얻을 수 있다. 생활데이터 그룹에 대한 소개는 아래를 참고하기 바라며, 회원으로 활동하기 위해서는 페북 그룹에 가입 신청을 하고 간단한 가입 양식을 작성하면 된다.
생활데이터는 수동적인 배움이 아닌 실천으로서의 데이터 과학을 뜻합니다. 부담 없이 서로의 문제 해결 과정을 공유하며 데이터 마인드를 키워나가는 커뮤니티를 지향합니다.
생활데이터는 주변에서 데이터 문제를 찾고 해결하는 과정을 나누실 분들을 주 대상으로 합니다. 다른 사람의 문제 해결에 참여하고 도울 용의가 있으신 분들도 환영입니다.
생활데이터는 그룹 월을 통해 데이터 활용 사례 및 방법을 나누고, 데이터 관련 궁금증을 풀어보는 행아웃 정모를 개최합니다.
- 생활데이터 페북 그룹: https://www.facebook.com/groups/livingdata/
- 생활데이터 가입 양식: https://goo.gl/MW1JYE
생활데이터 그룹의 첫 모임이었던 작년 12월 모임에는 서두에 소개한 서영부님을 비롯한 스무 분이 참석하셨다. 이중 현재 카이스트에 대학원에 재학 중이신 박건우 님은 피트니스 앱 사용을 지속하는 사용자들의 특징을 소셜 미디어 데이터로 분석하셨고, 모임에 참석은 못 하셨지만 김영웅 님은 지하철 데이터를 분석해서 연말에 붐비지 않고 데이트를 할 수 있는 장소를 시각화한 결과를 공유하셨다.
올해도 생활데이터 모임에서는 온라인 정모를 통해 자기 주변의 데이터 활용 사례와 방법을 꾸준히 공유할 생각이다. 필자와 함께 국내 여러 유명 데이터 과학자들과 생활 데이터 애호가들이 활발히 활동하고 있다. 데이터 과학을 실습과 경험을 통해 배우고자 하는 분, 데이터로 꼭 풀어보고자 하는 문제가 있는 독자 여러분의 많은 참여를 바란다. 이어지는 글에서는 생활 데이터를 시작하는 방법을 자세히 다루도록 하겠다.
추신: 이 글에 내용에 대한 의견 및 궁금증이 있으시면 꼭 댓글로 알려주세요. 데이터 활용에 관한 더 많은 이야기를 제 블로그와 페이스북, 트위터에서 만나실 수 있습니다.