
… 통계(calculations)와 그래프를 모두 만들어라! 정확한 이해에 기여하는 이 두 결과물에 대한 연구를 해야 한다.
F. J. 앤스콤브(Anscombe), 1793년(데이터 시각화에 관한 거의 모든 강의에서 반복한…)
일반적으로 사람들은 데이터 시각화를 데이터 분석 결과를 다른 사람들에게 보여주기 위한 수단으로 보는 경향이 있다.

하지만 데이터 시각화는 단순히 데이터 분석 결과를 전달하기 위한 목적뿐만 아니라 정확한 분석을 위한 데이터 탐색 방법으로 활용되기도 한다. 데이터 분석 과정에서도 시각화가 중요한 역할을 한다는 의미다.
‘숫자’ 만 봐서는 인사이트를 알 수 없다
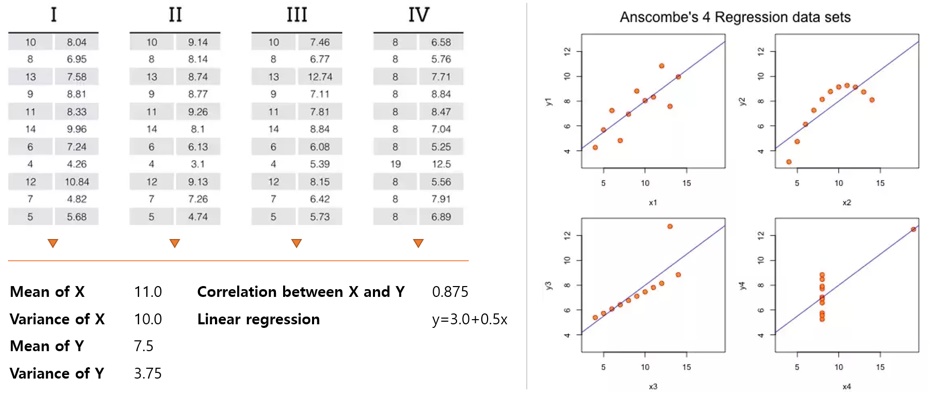
그림 1.22는 1973년 F. J. 앤스콤브(Anscombe)가 개발한 ‘앤스콤브의 4종류 데이터’다. 동일한 요약 통곗값(평균, 표준편차, 상관관계)을 가진 데이터셋(data set)을 산점도로 시각화했을 때 명확히 구별되는 시각적 패턴을 입증한다. 이에 따르면 요약 통곗값 정보만으로 데이터를 정확하게 파악할 수 없음을 이해할 수 있다. 우리는 요약 통곗값뿐만 아니라 시각화를 활용할 때 데이터를 정확하게 볼 수 있다.
정확한 이해를 위해서는 ‘보아야’ 한다
오랜 시간 동안 인용돼온 ‘앤스콤브의 4종류 데이터’에 이어 같은 맥락의 새로운 연구 결과를 살펴보자.
오토데스크 리서치(Autodesk Research)에서는 「같은 통계, 다른 그래프: 시뮬레이션 어닐링을 활용한 다양한 형태의 동일한 통계 데이터셋 생성」37이라는 제목으로 같은 요약 통곗값을 갖고 있으나 시각화했을 때 시각적 패턴이 뚜렷하게 구분되는 12개 데이터셋의 개발 결과를 발표했다.

그림 1.23은 데이터 시각화 분야의 유명 인사인 알베르토 카이로(Alberto Cairo)의 데이터 셋인 데이터 공룡(Datasaurus: 정상적인 통계처럼 보이지만 시각화하면 공룡 모양의 형태를 보임)과 소수점 두 자리수를 기준으로 같은 요약 통곗값을 갖는 12개의 데이터셋을 시각화했을 때 시각적 패턴이 모두 다르다는 것을 보여준다.
데이터 분석 과정에서 시각화는 필수다
두 가지 연구 결과를 바탕으로 우리는 데이터의 정확한 이해를 위해 데이터 분석 과정에서 시각화를 필수적으로 활용해야 한다는 점을 이해할 수 있다.
데이터 분석에서 ‘시각화’는 데이터의 정확한 이해를 위해, 또 쉽고 빠른 데이터 인사이트 발견을 위한 필수 요소라고 할 수 있다. 다른 한편으로 이를 ‘시각적 분석의 필요성’이라고도 요약할 수 있다.
시각적 분석이란 데이터 분석 방법으로서 시각화를 활용하는 것이다. 시각화 차트를 만들 때 활용하는 데이터 변수, 수치 계산 방식, 차트 유형 등의 조건을 달리하면서 다른 형태로 표현되는 시각화 차트의 시각적 패턴을 근거로 데이터 분석을 하는 것이다.
원문: NEWS JELLY의 블로그
참고자료
- Justin Matejka, George Fitzmaurice, 「Same State, Different Graphs : Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing」, 2017
- 위키백과, ‘Anscombe’s quartet’
- Justin Matejka, George Fitzmaurice, 「Same State, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing」, 2017