
커머스 혹은 유통 도메인 설계에 대한 연작 내용 중에서 아래 그림이 있습니다.
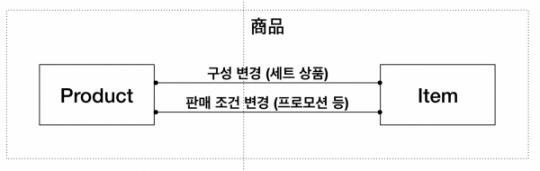
그림 설명으로 계층이란 표현을 썼지만, 그림 자체에는 계층의 어떤 내용도 없습니다. 연작이기 때문에 뒤에 쓴 다른 글에 계층을 왜 두었는지 설명이 있을 뿐입니다. 그림만 보면 상품이라고 불리는 같은 개념을 구분해보고, 각각을 프로덕트(Product)와 아이템(Item)이라고 불러보자고 결정한 사항이라 할 수 있습니다.
어쩌면 위스토어에서 받았던 영감 중에서 상품의 판매/전시 단위와 재고/정산 단위를 비대칭 처리하는 영역에 해당하는 부분이 있습니다. 그 영감을 해석해서 의미 있는 결과를 만들 때가 오면, 더 풍부한 경험을 공유할 수도 있습니다. 아직 그 내용을 충분히 소화하지는 못했고, 기억하기 위해 찍은 아래 사진을 남겨 미래를 기약합니다.

향수를 자극하는 DDD
이번에는 같은 개념을 둘로 나누는 일에 관한 이야기를 쓰려고 합니다. 최근에 주변에서 DDD(Domain-driven design)를 말하는 페친이나 동료들이 있습니다. 10년 전쯤에 DDD에 푹 빠진 일이 있습니다(푹 빠진 것치고는 남긴 결과가 없는데, 흔적 수준으로 찾아보면 DDD 번역서 추천사를 제가 쓴 것으로 기억합니다. 맞나?). 하지만 생업으로 연결하지 못해 생산적인 결과는 낳지 못했습니다.
그래서 그런지 DDD는 저에게 미련 혹은 향수를 부르는 이름인데요. 최근에 주변에서 DDD를 말하는 이가 늘어서 DDD 책에서 다루는 두 가지 개념과 연결해서 위 그림을 바라보는 습작을 해봅니다.
- 바운디드 컨텍스트(Bounded Context)
- 엔터티(Entity)
습작의 효용은 요즘 DDD 공부하는 동료에게 도움이 될까 하는 막연한 기대입니다. 또 다른 동기는 필자 내면의 향수가 만들 수 있는 생산력을 몸으로 확인하는 일이기도 하죠.
바운디드 컨텍스트란 무엇인가?
DDD의 설명은 모델 사용에 익숙하지 않은 개발자에겐 쉽지 않을 듯합니다.
Multiple models are in play on any large project.
프로젝트에서 여러 개의 모델을 쓴다니 무슨 말인가요? 모델을 따로 두지 않고 코드를 작성하는 회사라면 관계가 없는 설명일까요? 그렇지 않습니다. 모델이라고 불리는 뭔가 눈에 보이는 형태가 없어도 사실 모델은 개발자의 머릿속에 존재합니다. 예를 들어 다른 사람이 짠 코드를 수정해야 할 때, 어떤 가정을 만드는데 임시로 머릿속에 존재하는 생각의 조직이 흔한 모델의 존재 방식이죠.
생각해보면 눈에 보이는 형태로 존재하면 문제가 잘 드러나서 모델을 보완 혹은 활용하기에 좋습니다. 하지만 일반적으로 코드 이외의 가시적인 다른 생산물을 또 만들어 유지하는 일은 쉽지 않습니다. 선진 개발 조직은 돌아가는 코드와 병행해 코드를 검증하기 위한 테스트 코드를 별도로 만들어 유지하기도 하는데, 테스트 코드의 작성 수준은 종종 논란이 되곤 합니다. 그래서 명시적으로 모델을 만들어 공유하지 않고 개발자들이 함께 개발하는 일은 흔히 봅니다.
그러다 보면 비슷한 업무지만 조금씩 다른 업무를 함께 개발하는 개발자들 사이에서 유사한 개념을 조금씩 다르게 사용하는 일이 생깁니다. 처음에는 별문제가 아니지만, 차츰 쌓이면 생각지 못한 경직성이 만들어집니다. 쉽게 말해 고치기 어려워지는 일이 갈등과 공포를 만들어내곤 하죠. 소프트웨어 공학에서 결합(Coupling)이라고 해 부정적으로 취급하는 현상이기도 합니다.
예를 들어 설명해보겠습니다. 상품 정보를 다루는 프로그램 작성자가 Product라는 테이블을 만들어서 썼습니다. 그런데 다른 개발자가 기획자에게 새로운 요구를 받습니다. 실제 상품 사양이 확정되지 않았지만, 대략의 세트 구성으로 상품 이미지를 올려서 홍보할 수 있게 프로그램을 고쳐달라고 합니다. 그리고 가격과 사양을 확정하면 팔 수 있게 해달라는 것이죠.
뭔가 기존 상품과 다른 듯하지만 개발자는 기존 프로그램과 테이블을 최대한 활용하기 마련입니다. 그러면 Product 테이블에 세트 속성(이를테면 isSet)을 추가하고 이런 경우 재고 수량 계산 등의 방식이나 화면에 보이는 정보를 조금 다르게 표현하도록 프로그램을 수정합니다. 여기까지는 큰 문제가 없는데 만일 한참 후에 세트 상품이 팔리기 시작할 때, 재무 처리 문제를 책임지는 사람이 나타나서 세트 상품을 구성하는 실제 상품의 매입처와 정산할 수 있는 기능을 요구합니다.
이때는 간단한 필드 하나 추가하고 분기 로직을 조금 짜는 수준으로 문제가 해결되지는 않습니다. 이렇게 같은 개념도 맥락이 달라질 때 구분해서 보면 서로 다른 문제로 바라볼 수 있습니다. 복잡한 문제를 잘라서 서로 다른 문제로 나눠 취급(Divide-and-Conquer)하는 것이죠.
같은 말도 맥락에 따라 다르게 쓰입니다. 당연한 일이죠. 하지만 프로그램 내부에서는 어떤 단어가 어떤 맥락에서 쓰이는 말인지 구분하려면 세심한 노력이 필요합니다. 프로그램 내부에서는 어떤 단어가 패키지, 클래스 혹은 구조체, 함수, 변수 등등 어디에서 쓰이느냐에 따라 맥락을 상황에 맞춰 파악해야 합니다.
DDD에서는 복잡하고 규모가 커지면 맥락의 경계를 명확하게 정의하라고 제안하는데 그런 구분 단위가 바운디드 컨텍스트입니다. ‘어떻게 합니까?’라고 물으면 DDD는 방대한 실천 방법을 던져줍니다. 아래 그림 한 장으로 요약할 수 있습니다.
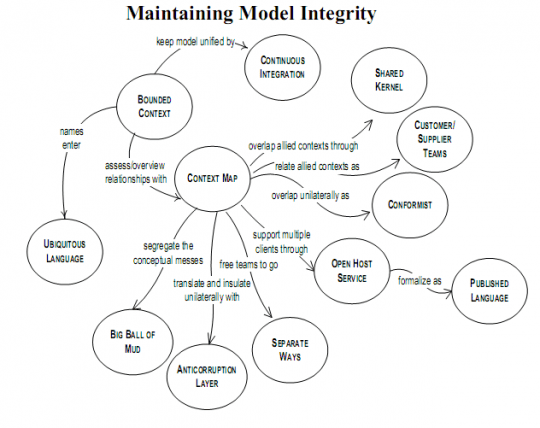
그림 역시 간단치가 않고, 책을 통해 글자로 보면 버거움을 느낄만한 분량과 내용이죠. 개발자라면 DDD 책 자체보다는 도메인 주도 설계 구현 책이 조금 나을 수 있지만, 두께가 만만치 않고 구현이 자바 기반이라 다른 언어를 쓰시면 공부가 쉽지 않습니다. 유익한 내용이지만 그만큼 노고가 따릅니다.
마이크로 서비스와 만나는 지점
앞서 소개한 책들의 출간 시점에는 마이크로 서비스가 개념으로 잡히지 않았습니다. 당연히 바운디드 컨텍스트를 다룰 때 마이크로 서비스 언급이 없습니다. 하지만 바운디드 컨텍스트를 마이크로 서비스 구성단위로 봐도 무방할 정도로 상당한 유사성을 가집니다(이 내용은 실제 반영 결과가 아니라 현재 시점에서는 그저 가정입니다).
상품을 Product와 Item으로 나눠보기
여기서 연재에서 사용한 우리의 예제를 살펴봅니다. 상품을 두 개의 바운디드 컨텍스트로 나눠보자고 결정했다 가정합니다.
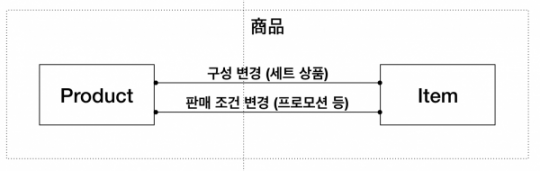
맥락이 달라지는 내용을 대강 요약하면 이렇습니다. 이 내용은 실제 반영 결과가 아니라 현재 시점에서는 그저 가정입니다.
Product
- 공급 상품 기준으로 판매액과 수량이 알고 싶다
- 실물 상품 코드 기준으로 식별이 가능해야 한다
- 공급 상품의 매장 도착 시각 등을 확인할 때 기준을 제시한다
Item
- 공급 상품 기준으로 팔 수도 있지만 세트 구성을 할 수 있다
- 특정 기간에만 할인을 적용할 수 있다
- 공급 업체와 대금 정산할 때 기준을 줄 수 있어야 한다
- 매장에서 손님 기호에 맞춰 상품 구성을 바꿀 수 있게 유연성을 준다
여기까지가 바운디드 컨텍스트 개념 적용 예시입니다.
DDD의 엔터티
이제 다음으로 DDD에서 말하는 엔티티 개념을 서로 비슷하게 알기 위해 위키피디아를 찾아봅니다.
An object that is not defined by its attributes, but rather by a thread of continuity and its identity.
속성으로 정의하지 않는다(not defined by its attributes)는 말은 무슨 뜻일까요? 사실 ERD를 읽고 쓸 수 있으면 거기에 나오는 엔터티와 크게 다르지 않습니다. 기업용 프로그램 작성 경험이 있는 분은 장부에 기록하는 단위인 레코드가 관계형 데이터베이스를 만나면서 관리번호를 부여해 관리하는 적절한 테이블 집합을 정의하는데 그것이 바로 엔터티입니다.
레코드 식별자를 주키 혹은 PK(Primary Key)로 배운 분들은 이미 엔터티를 만들어 써왔다고 할 수 있습니다. 다만 객체지향으로 혹은 객체란 개념으로 그 결과물을 보지 않았을 뿐이죠. 객체의 조직이란 관점으로 프로그램을 구현한다면 데이터베이스에 구현한 구조와 값 자체도 객체의 일부입니다(이를 캡슐화(Encapsulation)라고 부르기도 하죠).
따라서 뭐든 객체라는 단위로 구현 결과를 바라볼 수 있습니다. 그렇다면, PK는 바로 식별을 위한 값을 영구 보관하기 위한 장치입니다. ‘영구 보관’이란 표현이 필요한 이유는 메모리는 전원이 나가면 보관을 못 하니 저장소에 기록했다가 연산이 필요할 때 다시 복원해야 하기 때문이죠.
복원하려면, 애초에 개발자(설계자)가 원한 객체를 구성하는 속성이 채우는 집합을 지정해주어야 합니다. 하나의 객체 속성값의 집합을 나타내주는 개념이 필요한데 우리가 흔히 PK를 기준으로 데이터를 저장했다가 복원하는 것이죠. 흔히 ORM이라고 부르는 도구들이나 과거의 SQL Mapper가 이런 작업을 간소하게 해주는 도구입니다.
그 때문에 프로그램에서 지속적으로 상태변경을 할 수 있습니다. 전산화라고 부르는 행위 중에 가장 큰 영역이라 할 수 있는 종이 장부를 대체할 방법이 만들어진 거죠. 이때, 레코드 필드 값은 자유롭게 바꿀 수 있습니다. 사용자가 알아볼 수만 있으면 말이죠. 그 알아본다는 말이 식별 영어로 identity이고, 자유롭게 바꿀 수 있다는 말이 속성으로 정의하지 않기(not defined by its attributes) 때문이기도 하죠.
상품을 Product와 Item으로 나누면 엔터티는 무엇인가?
설명이 길었는데, DDD의 엔터티와 ERD의 엔티티가 공존하는 대한민국 현실에서 둘의 관계 설명이 한글 자료는 드물어서 시도해봤습니다. 이제는 연재에서 사용한 우리의 예제를 살펴봅니다. 상품을 이렇게 둘로 나누려고 하면 엔티티는 어떻게 될까요?
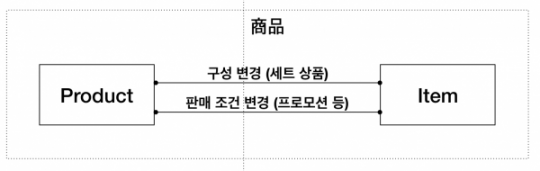
당연한 말이지만 정답은 없습니다. 필자의 상황에서 필자라면 둘 모두를 엔티티로 구현할 듯합니다. 정답이 없다고만 표현하며 무책임하게 글을 쓰는 듯해, 설계를 결정짓는 가장 큰 변수 둘을 제시한 표현입니다. ‘필자의 상황에서 필자라면’ 문장은 다음과 같이 형식화 할 수도 있겠네요.
설계 함수 = f( 도메인, 설계자)
그런데 둘 사이에는 밀접한 연관 관계가 있습니다. 예를 들어 오늘 동료 개발자가 Item에 sku 속성을 Product의 sku 단위와 1:1로 대응시켜 그 값으로 채우는 경우만 먼저 다루겠다고 합니다. 이는 item 구현에 있어서 물리적으로 공급받은 상품 1개와 대응하는 경우 먼저 구현하겠다는 표현이죠.
이렇게 구현한다고 하면, Item 엔터티를 조회할 때(혹은 메모리에 올릴 때) 어떤 상품과 연결하는 품목인지 알고자 할 수 있습니다. Item을 우리말로 바꿔 자연어 대화 같은 시도를 해보았습니다. 이런 경우는 조회 작업의 주체로 쓰이는 엔터티와 그렇지 않은 엔터티가 존재할 수 있습니다. DDD의 또 다른 빌딩 블록인 Aggregate가 떠오르는 지점입니다.
원문: Popit