
항상 추울 때 했었는데 장미 대선이라니, 왠지 묘하다. 당연히 요즘 이슈는 대선 후보 토론회. 지난 19일 2차 토론회가 끝났는데, 안 본 사람(나?)이 승자라는 우스개가 난무하길래 토론회 전문을 찾아봤다.
전문을 보고 있자니 호기심 발동. 텍스트 관계망을 분석해봤다.
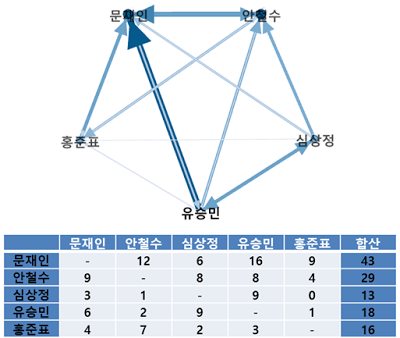
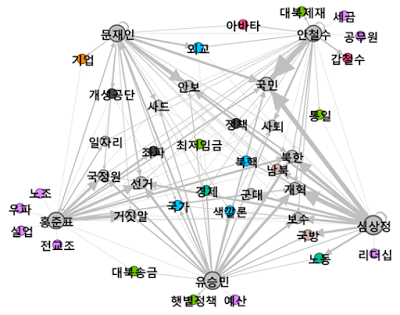
다음은 후보자별로 타 후보자를 언급한 빈도를 통해 살펴본 상호 관계망. ‘문 후보’ 등의 호칭은 이름으로 변환 후 작업했다. 1차 토론회는 ‘문재인-안철수’ 양강 구도 시작?
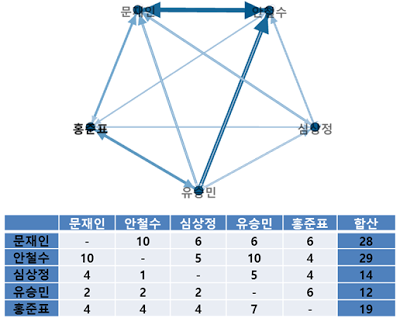
2차 토론회는 양상이 조금 바뀌었다. 분위기 파악 끝난 듯. ‘문재인 청문회’였다더니, 안철수 후보도 만만치 않은 타깃이 됐던 모양. 그런데도 주목을 끌지 못한 이유는 질문 수위 차이인가?
문재인의 키워드
2차 토론회에서 언급된 (내 맘대로 선별한) 문재인 후보의 키워드. 언급 비중이 높은 순은 다음과 같다.
- 북한
- 남북관계
- 국방
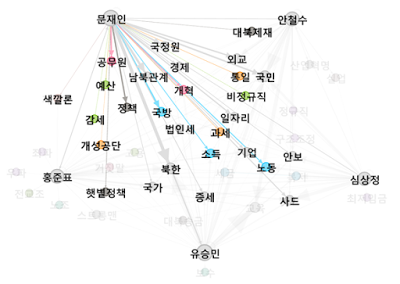
문재인 후보의 TOP1 키워드인 ‘북한’에 대한 타 후보의 비중. 누구와 설전을 주고받았는지 대충 느낌이 온다.

안철수의 키워드
다음은 안철수 후보의 키워드.
- 국민
- 교육
- 외교
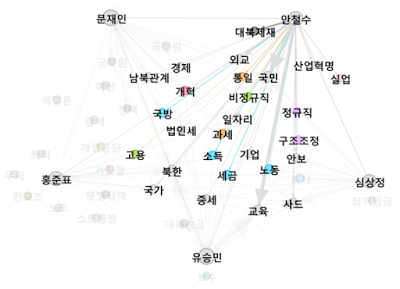
안철수 후보의 TOP1 키워드인 ‘국민’에 대한 타 후보의 비중은 다음과 같다.

심상정의 키워드
다음은 심상정 후보의 키워드 언급 비중.
- 사드
- 국민
- 노동(또는 안보?)
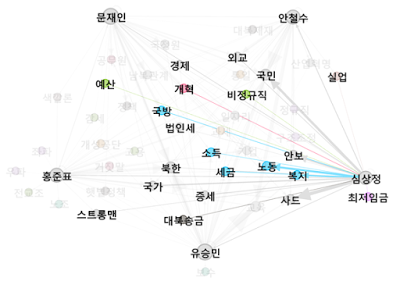
TOP1 키워드인 ‘사드’에 대한 타 후보의 비중.
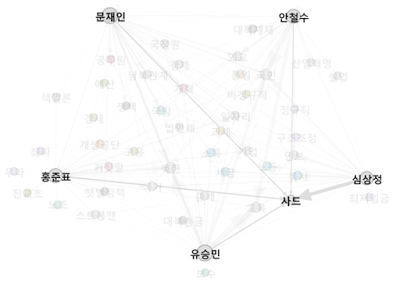
유승민의 키워드
다음은 유승민 후보의 TOP3 키워드.
- 교육
- 북한
- 국민
숨 고르기 중인 문재인, 심상정 후보.

홍준표의 키워드
마지막으로 홍준표 후보의 TOP3 키워드.
- 북한
- 국가
- 기업
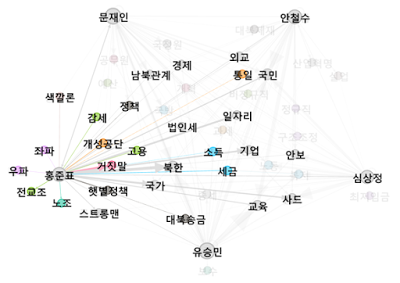
(‘북한’은 문재인 키워드 부분에서 언급했으므로) TOP2 키워드인 ‘국가’의 타 후보 비중.

텍스트 관계망을 이용해서 토론회 분위기를 살펴봤다. 하지만 단순 텍스트의 나열 관계만으로 섣부른 추측은 곤란. 원본 데이터와의 맥락 비교가 필요하다는 뜻이다. 내가 ‘북한’을 키워드로 한 문재인, 유승민 후보의 설전을 추측할 수 있었던 이유는 전문을 이미 봤기 때문.
보통 정확한 데이터 모델링 전에 데이터에 대한 이해도를 높이기 위해 이런 분석을 많이 하는데, 유식하게 표현하면 탐색적 데이터 분석(Exploratory data analysis)이라고 하며, 데이터 발생 빈도 등의 정보를 통계나 도식화 등을 통해 시각화하는 방법을 많이 사용한다.
이왕 살펴본 김에 토론 전문의 가독성도 살펴보자. 영어권에서 글의 가독성을 측정하는 거닝 포그 지수(Gunning Fog Index, GFI)라는 게 있다. 문장을 읽고 이해하는 데 필요한 교육 수준을 나타낸다고(그런데 한글 가독성 측정에도 적합한가?).
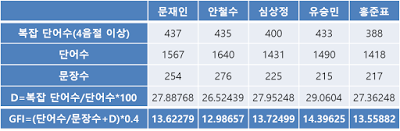
트럼프와 클린턴의 대선 토론 GFI가 6~8(초6~중2) 수준이었는데, 우리 후보들의 토론은 전문 학술지 이상의 수준을 보인다. 물론 실제 그럴 리는 없고, 복잡한 단어를 길이 조건으로만 선별한 결과(본격 발 분석^^;). 정확하게 하려면 익숙한 용어 및 복합어 등의 배제 과정이 필요하다고.
실제 GFI 수준은 절반 정도로 보면 될 듯하다. 초6~중1 수준? 이게 나쁘다는 뜻은 아니다. 다양한 계층의 대중을 대상으로 하는 연설문 등은 이해도를 높이기 위해 일부러 쉽고 친근한 표현을 사용하는 게 일반적이다.
3차 토론 이후
지난 4월 23일 열린 대선 후보 3차 토론회의 분석을 덧붙인다.
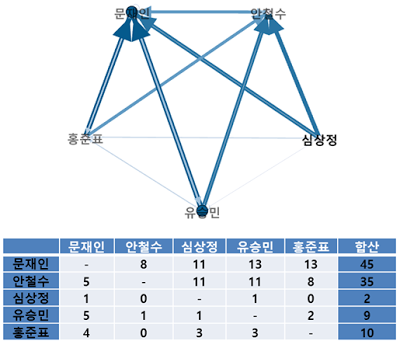
다음은 후보자별로 언급한 타 후보 비중. 2차 토론 이후로 피아 식별 끝난 듯?
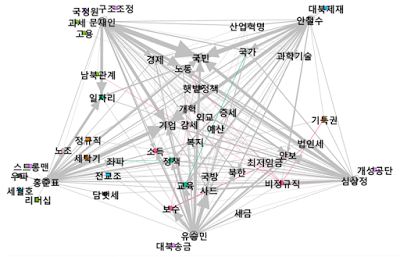
1-3차 토론 키워드 발생 분포
뒤로 갈수록 밀도가 줄어드는 것처럼 보인다.
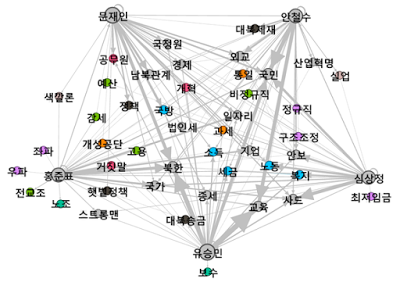
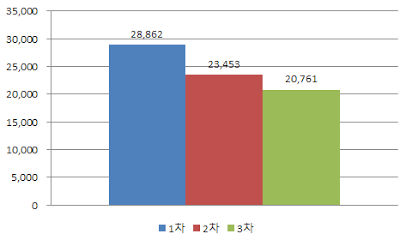
실제 키워드 개수가 1차 46개 → 2차 44개 → 3차 39개 순으로 줄었으며, 후보자 간에 주고받은 전체 글자 수도 3차에서는 1차 대비 70% 정도 줄었다. 피로도 쌓였을 테고, 반복되는 공방 속에 후보자들 나름 적응이 된 듯(심상정 후보의 깜짝 사회자 역할도 한 몫?).
총평
심상정 후보의 한마디 빼고 재미없더라.
“북한 없었음 보수가 어떻게 선거했겠나?”
앞으로도 안 본 사람이 승자가 될까? 성숙한 토론 문화의 정착을 위해서라도 토론다운 토론을 기대해본다.
원문: 케세라세라