
유전 알고리즘과 하스스톤
올해 우리나라 커뮤니티 사이트에서 흥미로운 글을 읽었다. 우리나라 고등학생이 쓴 글(안해담, 자연선택의 원리를 이용한 전략 카드게임 인공지능 향상 가능성에 대한 연구; 이하 하스스톤 인공지능 향상 연구)로 블리자드 사의 인기 TCG 게임 하스스톤의 인공지능 플레이어에 유전 알고리즘을 적용하고 그 결과를 쓴 글이었다.
‘하스스톤’과 ‘유전 알고리즘’ 이두가지 키워드 모두 필자의 호기심을 자극 하였다. 처음 하스스톤을 플레이 했을때에는 너무 재밌는 나머지 노트북을 침대에 가지고 들어가 누워서까지 플레이 했었다.
학교 수업 중에선 인공지능 수업이 가장 흥미롭고 자극되는 수업이었다. 당시에는 신경망 알고리즘 내용에 더 집중했었지만 다시금 유전 알고리즘에 대해선 살펴볼 필요가 있었다.이런 계기로 틈틈히 알아본 유전 알고리즘에 대한 내용을 공유해보고자 글을 쓰게 되었다.
유전 알고리즘을 이야기 하기 앞서 용어를 정확히 해야겠다. 유전 알고리즘 관련 도서나 자료를 살펴보기 전까지는 ‘유전 알고리즘’과 ‘유전자 알고리즘’이라는 단어를 혼용해가며 사용했었다. 하지만 이는 잘못된 표현으로 ‘유전 알고리즘’이 맞는 표현이다. 우리가 살펴보고자 하는 유전 알고리즘은 유전자의 모습을 고안하거나 이용하는 것이 아니라, 세대가 바뀌어 가며 유전되는 행위 그 자체를 모델링하는 것이다.
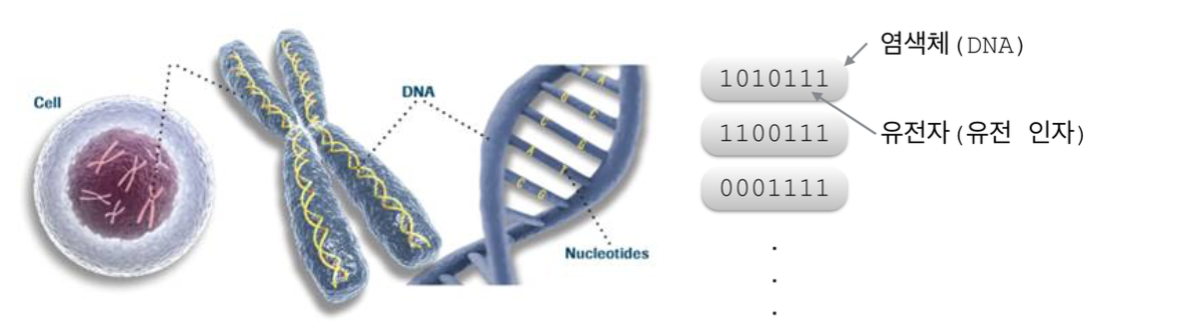
생물의 염색체가 유전 정보를 담고 있는 것처럼 유전 알고리즘에서도 염색체와 유전자가 유전 알고리즘의 기본적인 구조를 구성한다. 염색체와 유전 인자는 문제의 속성과 시간 자원등을 고려하여 유전 알고리즘이 이해할 수 있는 해의 형태로 설계하여야 한다.
문제에 대한 해를 표현하는 염색체가 집단을 이루어 해집단을 구성하고 유전 알고리즘의 진행 과정속에서 부모 세대와 자식 세대의 역할을 반복적으로 하게 된다.
유전 알고리즘의 과정
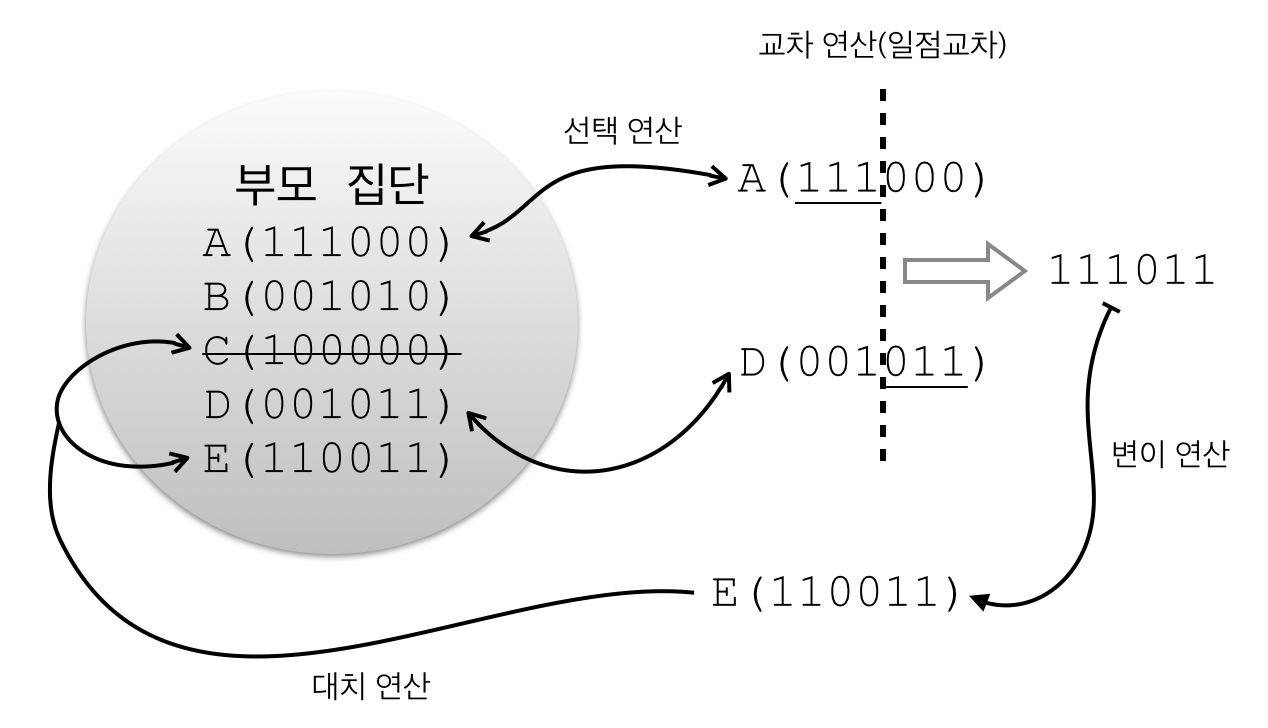
유전 알고리즘의 과정을 간략히 살펴보면 먼저 선택 연산을 통해 교차 연산을 적용할 부모를 선택한다. 교차 연산은 생물학에서의 유성생식 과정과 유사한 과정으로 두 부모간의 유전자 교차를 통해 부모의 유전적 특징을 갖는 새로운 자식을 생성하는 과정이다.
생성된 자식에게는 생물학에서의 돌연변이 발생 과정과 같이 변이 연산이 적용될 수도 있다. 선택 연산, 교차 연산, 변이 연산을 통해 생성되는 자식 세대는 대치 연산을 통해 새로운부모 세대로 대치된다. 거듭되는 유전 과정을 거쳐 세대가 진화함으로써 문제에 대한 최적해에 접근하게 된다.
위키피디아의 유전 알고리즘 항목을 살펴보면 다음과 같은 내용이 있다.
“어떤 미지의 함수 Y = f(x)를 최적화하는 해 x를 찾기 위해, 진화를 모방한(Simulatedevolution) 탐색 알고리즘”
유전 알고리즘을 딱 한 줄로 잘 표현한 문장이라고 생각한다. 진화를 모방하기 위해 진화 과정에서 일어나는 일련의 생식과 세대 교체 과정을 선택 연산,교차 연산(교배 연산), 변이 연산, 대치 연산을 통해 모사한다.
유전 알고리즘 과정에서 실행하는 각각의 연산에 대해서 살펴보자. 선택 연산은 교차 연산을 적용하기 위해 해집단에서 부모 염색체를 선택하는 과정이다.전제되는 원칙은 우수한 유전자가 선택되어 좋은 유전자가 자식세대로 유전되어야 한다는것이다. 유전 알고리즘에서 말하는 좋은 유전자는 해결할 문제에서 최적해를 구성하는 유전자를 말한다.
우수한 정도를 판별하기 위해서는 적합도를 계산할 필요가 있다. 적합도는 해당 유전자가 문제 해결에 얼마나 적합한지를 나타내는 수치이다. 이 수치는 절대적인 의미보다는(‘이 값은 이 문제를 해결하는 완벽한 값이야!’ 혹은 ‘10% 부족해’ 가 아니다.) 해집단의 다른 유전자와 비교해 얼마나 적합한지를 나타내는 상대적인 수치(‘이 값보다는 적합한 값이다’ 처럼)로써의 의미를 갖고 있다. 계산한 적합도를 기반으로 선택압을 조절함으로써 우수한 유전자와 우수하지 않은 유전자를선택하는 비율을 조절한다.
앞서 이야기했던 하스스톤 인공지능 향상 연구를 살펴보면 30장의 카드로 구성된 덱을 염색체로 표현하고 카드 한장 한장을 유전자의 역할로 사용한다. 초기 해집단을 구성하기 위해 랜덤하게 마나 비용을 선택하고 마나 비용에 해당하는 카드를 또 랜덤하게 뽑아 30장 씩의카드를 선택하여 10개의 덱을 구성한다(마나 비용에 대해선 교차 연산을 살펴보며 설명하도록 하겠다.). 교차 연산을 위해 하스스톤에서 제공하는 마법사 인공지능과 대결하여 상위승률을 기록하는 4개의 덱을 선택한다. 선택된 4개의 덱을 서로 교차(교배)연사하여 새로운자식 덱을 생성한다.
상위 승률의 4개 덱을 선택한다는 점에서 마법사 인공지능과의 승률을 적합도로 삼았고 선택압은 매우 높았음을 알 수 있다. 선택압은 우수한 유전자와 우수하지 않은 유전자를 선택하는 비율을 뜻한다.
하스스톤 인공지능 향상 연구에서는 선택의 기준을 적합도(승률)만으로 삼고 있어 적합도가낮은 해들이 아주 적은 비율로도 선택되지 않고 있다. 이는 진화를 진행하는 과정에서 설익은 해에 수렴할 가능성을 높인다. 적합도가 낮은 해들도 낮은 비율로 선택하여 교차함으로써 유전적 다양성을 갖고 탐색 공간을 더 넓게 사용해 설익은 해에 수렴할 확률을 줄일 필요가 있다고 생각한다.
룰렛휠 선택
선택 연산의 방법으로 흔히 사용하는 품질 비례 룰렛휠 선택을 살펴보자.
해집단의 해 i의 적합도 fi는 다음과 같이 계산한다.

이때 k의 값을 프로그래머가 조절함으로써 선택압을 조절 할 수 있다.
수식에서 알 수 있듯이 k 값이 높을수록 해들의 적합도를 보정하는 #$%&$)’ 값이 줄어들게 되고 해들간 적합도 차이는 크게 변하지 않는다. 반면 k 값이 낮을수록 적합도를 보정하는 값은 크게 적용되어 해집단 내의 해들간 적합도 차이는 줄어들게 된다. 일반적으로 k 값은 3~4의 값을 사용한다고 한다.
이렇게 구한 적합도 값을 바탕으로 계산한 적합도 값을 모두 더하고 모두 더한 값을 전체면적으로 하는 룰렛을 만들어 각 적합도 만큼 해당 해를 배정한다.
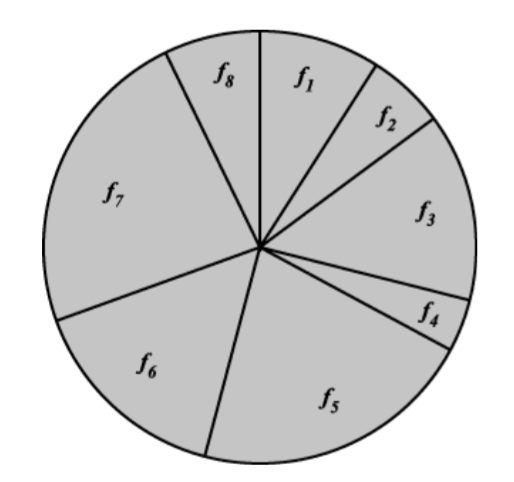
만들어진 룰렛휠을 돌리고 그 결과로 선택된 영역의 해를 교차 연산을 적용할 해로 사용한다. 룰렛휠을 돌리는 일은 랜덤 함수를 이용하여 구현하도록 하자.
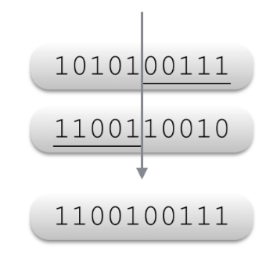
생물학에서 두 부모가 교배를 통해 새로운 자손을 생성하듯이 유전 알고리즘에서도 두 부모해가 교차 연산을 통해 새로운 자식해를 생성한다. 이때 교차 연산은 문제 해결에 영향을 미치는 두 부모해의 유전자적 특징을 조합하여 두 부모의 특징을 갖는 자식해를 만들어 가는 과정이다. 유전 알고리즘을 적용하면서 문제 해결에 영향을 미치는 유전자적 특징은 염색체 상의 어떠한 위치에서든 나타날 수 있다.
어떻게 교차할 것인가에 대해서도 충분한 고려가 필요하다. 문제 해결에 탁월한 유전자들이모여있는 품질 좋은 부모 염색체가 선택 되었다고 가정 했을 때 다점 교차를 적용하게 되면품질 좋은 염색체는 여러 부분으로 나뉘어져 자식해에게 전달되어 진다. 일점 교차의 결과보다 품질이 떨어지는 자식해가 생성될 가능성이 높다.
반면 다점 교차나 다른 교란이 큰 교차는 미미틱 유전 알고리즘(혼합형 유전 알고리즘)에서공간 탐색 영역을 크게 가져감으로써 일점 교차보다 더 중요하게 활용된다. 교차 방법을 결정하는데 있어 문제의 정의와 염색체의 표현, 유전 알고리즘의 구조 등 다양한 고려가 필요하다는 점을 생각하여야 한다.
또한 이러한 고민은 변이 연산에서도 동일하게 적용된다.
하스스톤 인공지능 향상 연구에서는 문제의 상황을 고려하여 나름의 방법대로의 교차 연산을 적용하고 있다.
먼저 교차 연산을 하기 위해 각 카드마다 구분할 수 있는 고유한 숫자를 할당한다. 할당하는 방법으로 각 카드마다 필요한 마나 개수를 카드를 구분하는 고유한 숫자의 제일 앞자리수(백의 자리)에 할당하도록 하였다. 하스스톤에서는 게임 규칙에 따라 카드를 사용하기 위해카드마다필요한마나수가정해져있다.예를들어전설등급카드 “실바나스윈드러너”의 경우 마나 비용을 6을 차지한다.
교차 연산을 적용하기 위해 선택한 두 카드덱(부모해)을 위에서 설명한 고유 숫자를 바탕으로 오름차순 정렬한다. 그리고 서로 같은 행에 있는 두 카드 중 무작위로 하나씩 선택하여새로운 자식해를 생성한다.
먼저 살펴본 일점 교차나 다점 교차와는 차이가 있어 보이는데 일점 교차나 다점 교차의 경우 염색체 상에 존재하는 유전자의 위치가 해의 품질(최적해와 비슷할수록 품질이 좋다)에영향을 미치는 요소로써 작용한다. 하지만 하스스톤 인공지능 향상 연구에서 표현한 염색체는 염색체를 구성하는 유전자의 위치(혹은 순서)가 문제 해결과는 연관이 없으므로(해의 품질에 영향을 미치지 않으므로) 일점 교차, 다점 교차와는 상관없이 문제 상황을 고려하여나름의 교차 방법을 고안한 것이다.
생물학에서는 다양한 요인으로 돌연변이가 발생한다. 많은 경우 별다른 영향없이 그대로도태되지만 때로는 이러한 돌연변이가 환경을 극복하는 요인으로 작용하여 진화하는데 큰 역할을 하기도 한다. 유전 알고리즘에서도 변이 연산을 통해 유사한 과정을 거친다.
두 부모해에서 찾을 수 없는 유전자를 낮은 확률로 자식해가 가짐으로써 돌연변이 염색체를 생성한다. 생성된 돌연변이 염색체가 낮은 비중이지만 해집단에 포함됨으로써 해집단의다양성을 확보하고 최적해 탐색 공간을 넓게 가져간다.
탐색 공간을 넓힘으로써 다양한 해를 탐색하고 최적해를 찾을 확률을 높이기도 하지만 탐색시간 또한 늘어날 수밖에 없다. 교차 연산에서 언급하였듯이 유전 알고리즘의 설계에 따라변이 연산 또한 적절히 고려되어야 한다.
미미틱 유전 알고리즘에서는 교란의 정도가 큰 변이 연산을 설계하여야 한다. 미미틱 유전알고리즘은 순수 유전 알고리즘과 문제 상황에 맞는 지역 최적화 알고리즘을 섞어서 만든 혼합형 알고리즘을 뜻하는데, 이런 혼합형 알고리즘에서는 교란이 적은 연산을 수행하는 경우 지역 최적화 알고리즘이 연산 적용 이전으로 되돌려버려 연산의 효과가 사라져버릴 수 있기 때문이다.
하스스톤 인공지능 향상 연구에서는 교차 연산으로 새로이 생성되는 자식 덱 6개 중 3개의 덱을 선택하고 각 덱마다 3장씩을 다시 선택하여 무작위 카드 3장으로 바꾸어 놓도록 변이연산을 수행한다. 적용한 변이 연산의 교란 정도가 크지 않다고 생각한다. 적용한 유전알고리즘이 지역 최적화 알고리즘과 혼합되지 않았고 순수하게 유전 알고리즘만 적용하였기에 교란의 정도가 큰 변이 연산은 필요하지 않은 것이다.
선택 연산, 교차 연산, 변이 연산을 통해 생성한 자식해는 기존의 부모해를 대체하고 새로운 부모해로서 역할을 하게 된다. 부모 세대를 대치하는 데에도 여러 방법이 있다. 생성한 자식해로 부모해를 모두 대치하는 방법, 부모해 중 품질이 좋지 않은 해만 대치하는 방법, 생성한 자식해와 부모해의 품질을 비교하여 품질이 더 좋은 해를 다음 세대로 결정하는 방법 등 직관적으로 생각해보더라도 다양한 방법을 생각할 수 있다.
자식해를 어떻게 대치하느냐에 따라서 해집단의 다양성과 수렴성이 달라지므로 교차 연산, 변이 연산과 함께 고려되어야 한다.
하스스톤 인공지능 향상 연구에서는 10개의 덱 중 상위 승률을 기록한 4개의 덱은 그대로다음 세대에도 포함시키고 그 4개의 덱을 서로 교배하여 나머지 다음 세대를 구성하는 6개의 덱을 생성하도록 한다. 예를 들어 <그림 5> 처럼 1번에서 10번까지의 덱 중 상위 승률을기록한 2, 5, 6, 7번 덱은 다음 세대에도 포함된다. 그리고 2, 5, 6, 7번의 덱을 서로 교배하여 나머지 다음 세대를 구성하는 6개의 덱을 생성하는 모습을 나타내고 있다.
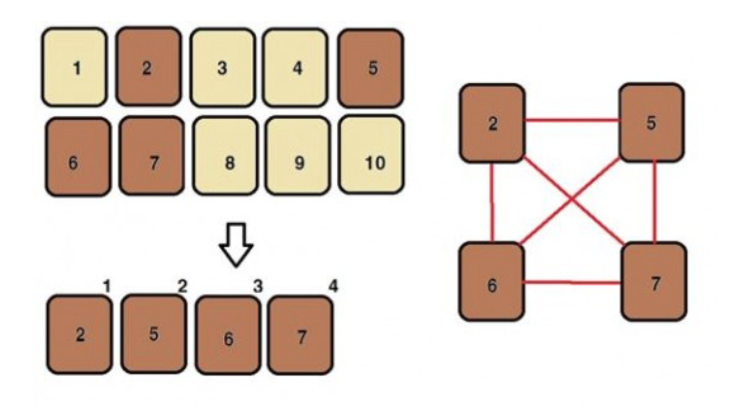
이런 유전 및 진화 과정을 5세대에 걸쳐서 진행하였고 결과적으로 하스스톤 인공지능 향상연구에서는 자연선택을 모사하는 유전 알고리즘을 통해 평균 승률을 23% 증가하는 유의미한 결과를 얻었다고 한다.
마치며..
이상으로 유전 알고리즘의 기본적인 연산 과정들을 살펴보았다. 유전 알고리즘의 연산 과정들을 반복해가며 새로운 세대를 형성하고 최적해에 접근해가는 과정을 반복한다. 유전 알고리즘은 최적해를 정확하게 구해가는 과정이 아니라 진화를 통해 다양한 해를 탐색해가며 최적해에 가까운 답을 찾아가는 과정이다.
실제 하스스톤 인공지능 향상 연구 내용에 대해서 더 알고 싶은 독자들은 참고 문헌을 참고하기 바란다.
- 쉽게 배우는 알고리즘<문병로 저>
-
자연선택의 원리를 이용한 전략 카드게임 인공지능 향상 가능성에 대한 연구(하스스톤인공지능 향상 연구) (링크)
-
<그림 1.> 생물학에서의 유전자와 유전 알고리즘에서의 유전자와 유전 인자 (링크)
-
<그림 3> 룰렛휠 공간 배정의 예 : 쉽게 배우는 알고리즘<문병로 저>
원문: hurdrella의 브런치