데이터 수집이 중요하다는데, 어떤 데이터를 수집해야 하지?
데이터 수집에는 품이 많이 든다. 데이터 작업 시간의 80%가 데이터를 수집하고 정제하는 데 소요된다. 개발자를 뽑자니 작은 회사에는 부담이고, 개발자가 귀한 시대라 있는 개발자도 자기 일하기 바쁘다.
그래서 데이터 수집을 자동화해주는 서비스들이 나왔다. 해외는 Import.io, zyte.com, 국내는 리스틀리가 대표적이다. ‘리스틀리’는 크롬/엣지에 확장 프로그램을 설치하여, 브라우저상에서 버튼 하나만 누르면 온갖 형태의 데이터들을 긁어와 엑셀로 만들어준다.
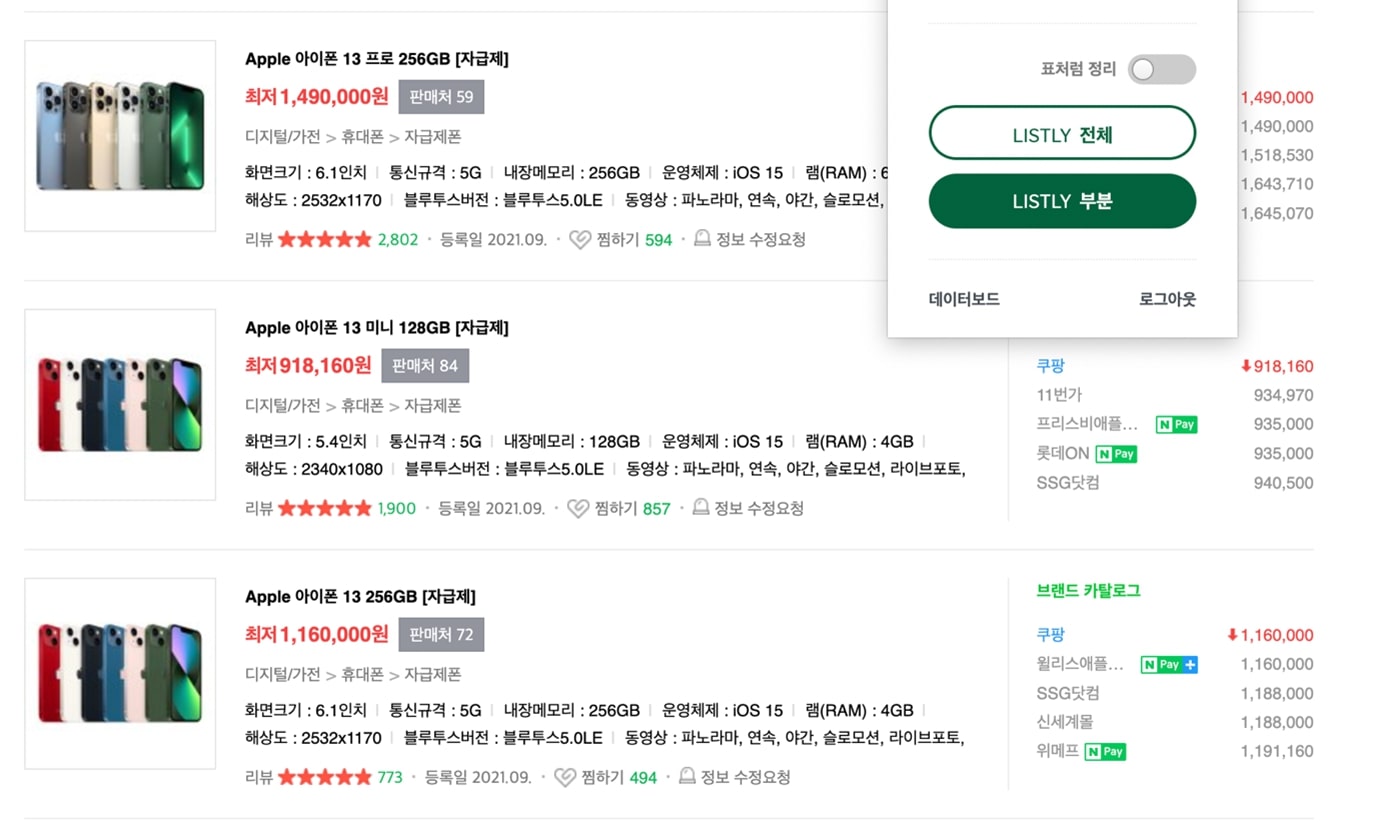
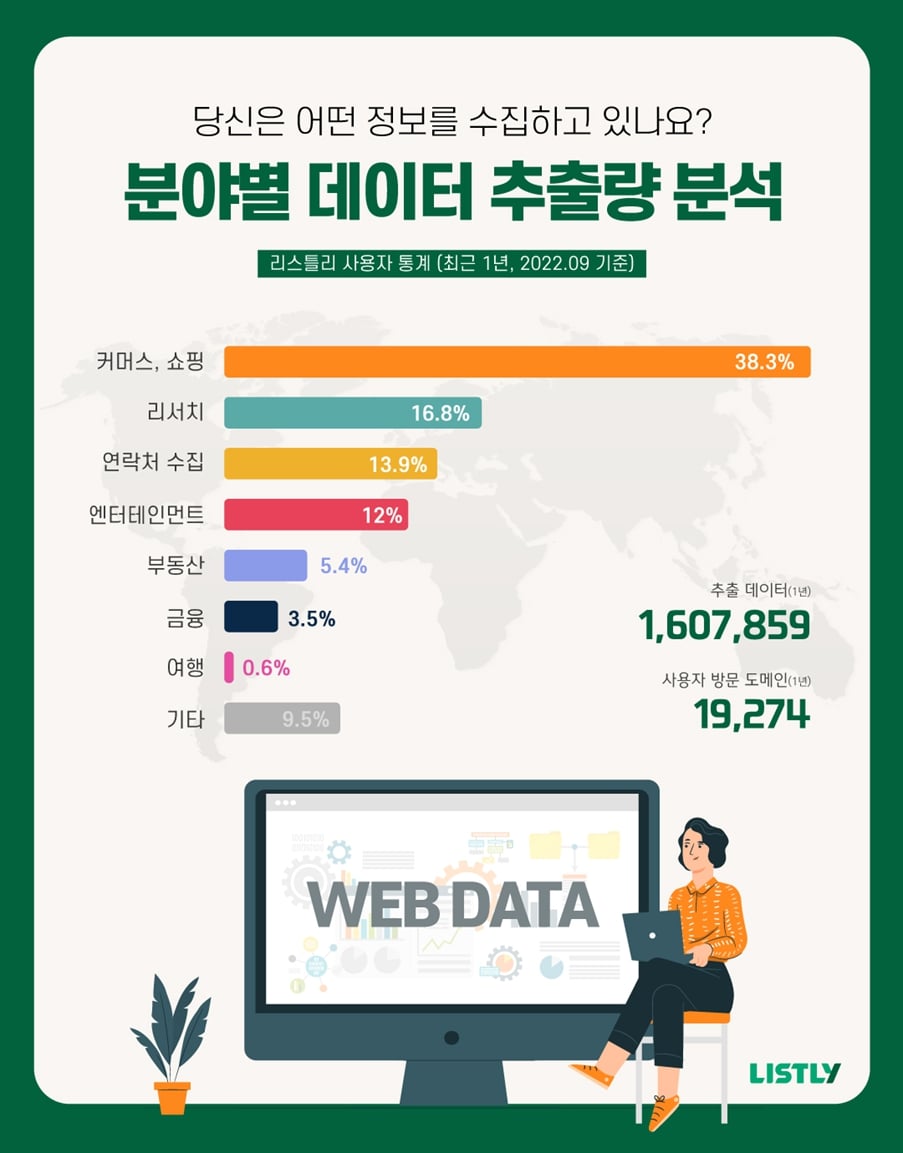
데이터 수집은 쉽다. 문제는 ‘어떤 데이터를 긁어야 할지’다. 데이터 수집 서비스 ‘리스틀리’는 10만 유저 돌파를 기념하여, 유저들이 어떤 데이터를 수집하고 있는지를 분석해 발표했다. 이를 토대로 업계별, 분야별로 어떻게 데이터를 활용하고 있는지 알아보자.
커머스, 쇼핑: 경쟁 쇼핑몰 및 도매몰 인기상품, 최저가 정보 긁어오기
커머스, 쇼핑 분야는 데이터 크롤링이 가장 많이 사용되는 분야다. 리스틀리 데이터에서도 38.3%의 데이터가 이 분야에서 수집됐다. 대표적인 예가 최저가 수집이다. 대형 쇼핑몰 A사는 오픈마켓에서 경쟁사의 상품 가격 정보를 긁어와 최저가를 맞춘다.
호텔 예약 플랫폼 B사는 포털에서 숙박 상품과 숙소 연락처를 수집하여, 상품을 업로드하고 새 상품을 개발한다. C 여행사는 주기적으로 항공권 가격 데이터를 수집하여, 이를 자사가 판매하는 패키지 상품에 반영한다.
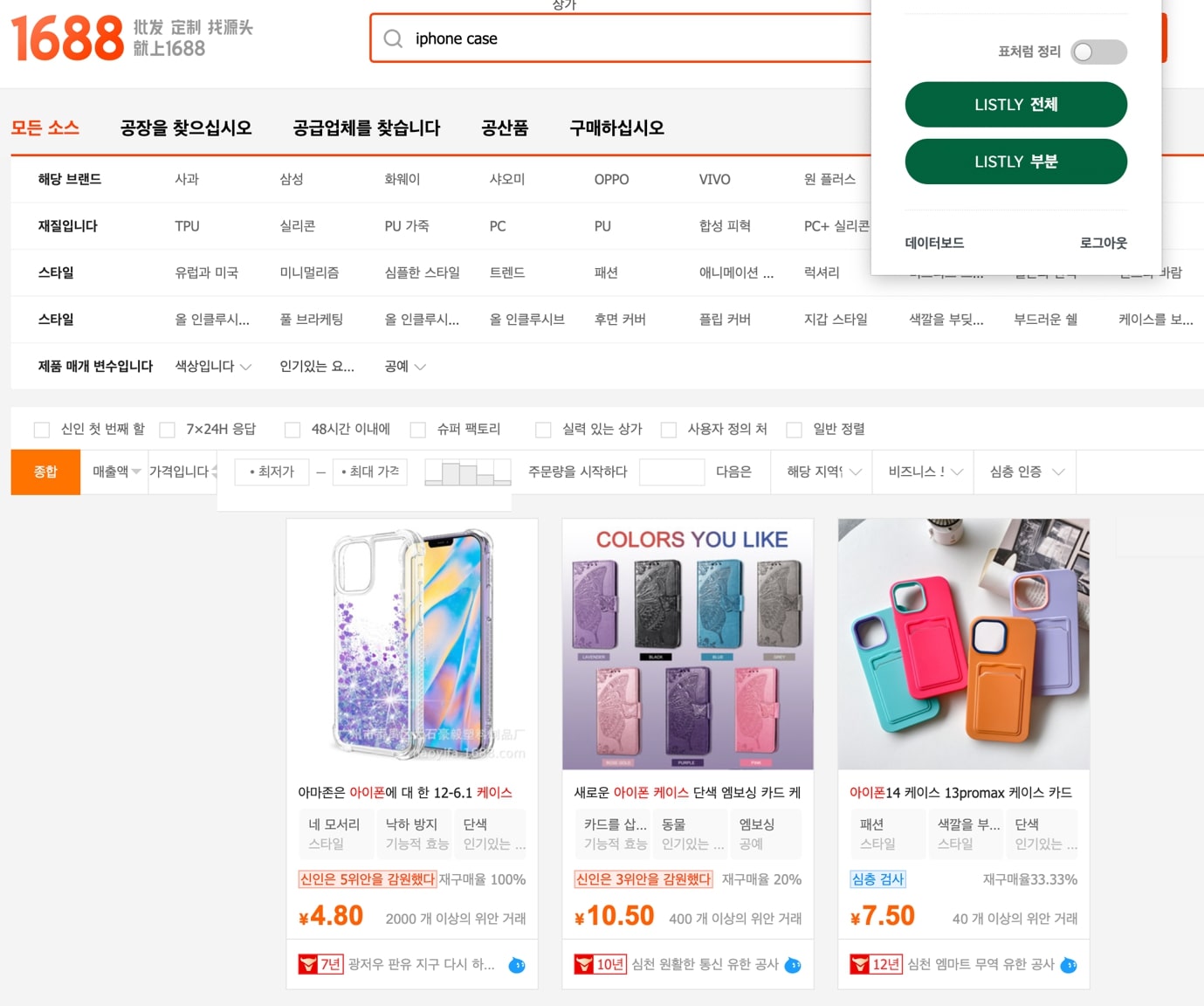
데이터는 언어의 장벽도 넘는다. 휴대전화 액세서리를 판매하는 D 소매몰과 구매대행 전문 E 쇼핑몰은, 중국 도매 사이트의 상품 데이터를 긁어와 자사 쇼핑몰 운영에 사용한다.
엔터테인먼트: 음원 순위/판매량 분석, 유튜브 인기 분석
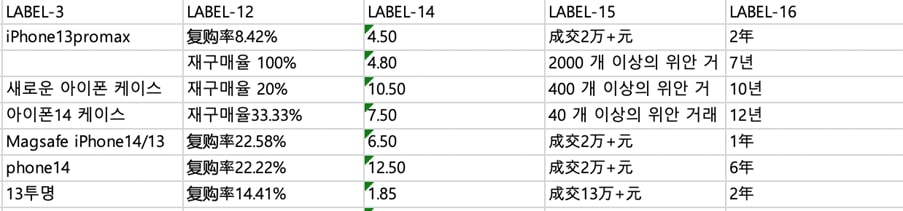
최근에는 엔터 분야에서도 데이터 수집의 중요성이 높아지고 있다. 음원 및 음반을 유통하는 F사는 음원 사이트의 순위와 재생 횟수, 신보 발매 상황을 매일 크롤링한다. 데이터 자체는 음원 사이트에 들어가면 언제든 볼 수 있다지만, 사이트별로, 일자별로 뿔뿔이 흩어져 있어 실제 활용하기 어렵다. 엑셀 등의 형태로 정량화할 필요가 있다.
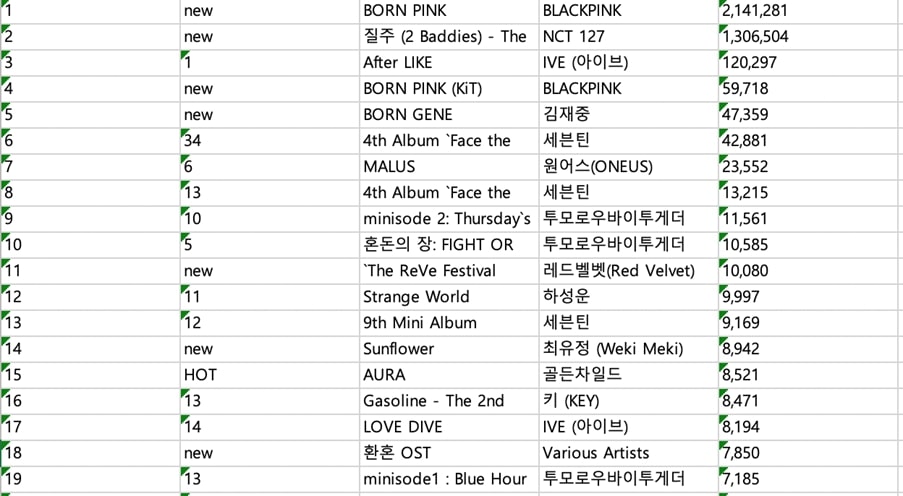
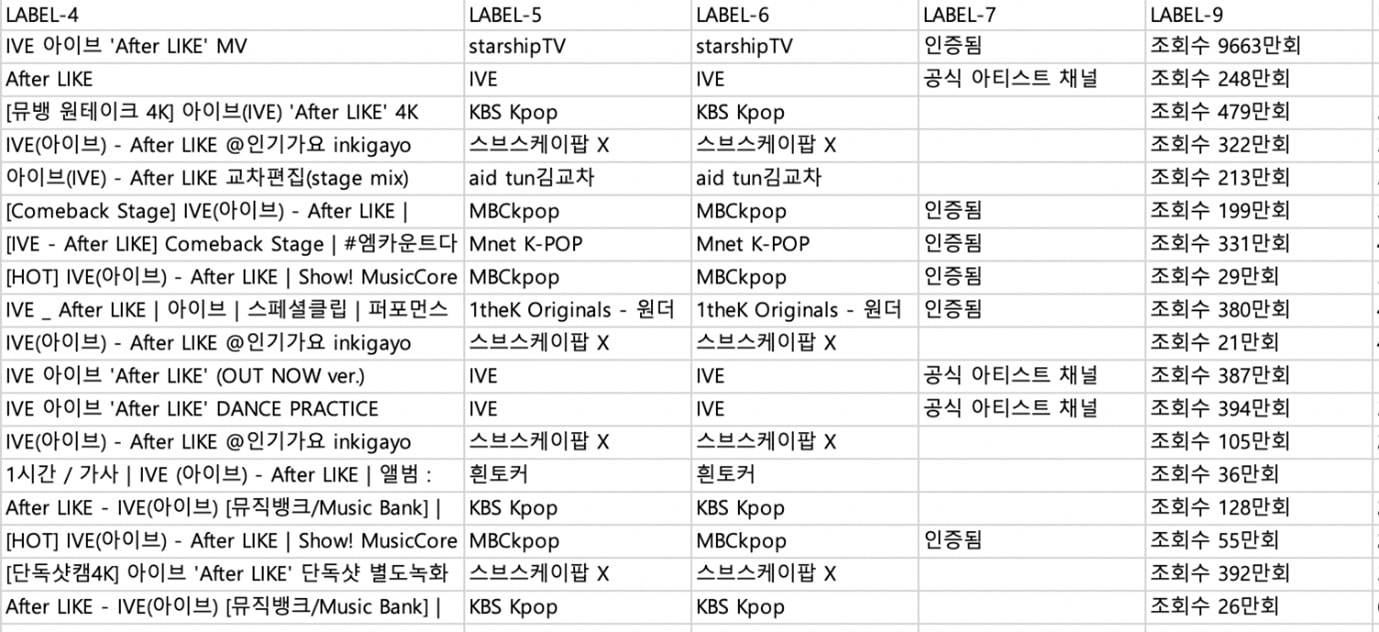
유튜브가 대세로 떠오르며 크롤링은 더 중요해졌다. 조회수 하나만 해도, 음원부터 뮤직비디오, 무대 영상, 팬 영상까지 봐야 할 데이터가 더 많기 때문이다. 긁어온 데이터를 엑셀로 펼친 후, 필터나 함수 등을 이용해 가공하여 살펴본다. 회사는 물론 팬들도 데이터를 활용한다. 가수 G의 팬클럽이 이렇게 데이터를 긁어와 음원 인기를 분석하고 음원 재생 ‘총공’ 등에 활용한다.
리서치: 공공/연구기관 데이터 수집, 뉴스 클리핑, 마케팅 성과 분석
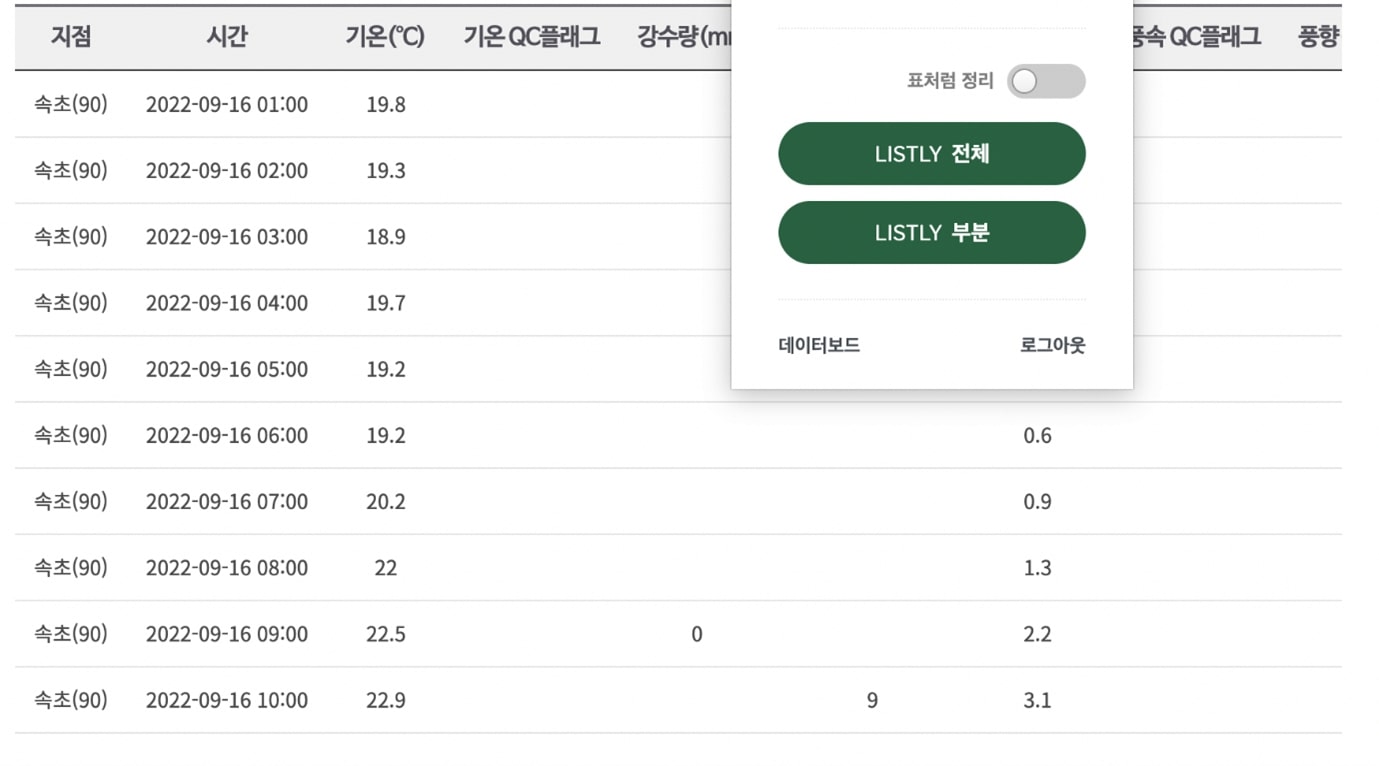
리서치는 데이터가 가장 직접적으로 사용되는 분야로, 16.8%의 데이터가 리서치 분야에서 수집되었다. 리서치 전문 기업 H사는 정부의 최신 공개 데이터를 지속적으로 수집하여 경기, 시장 동향을 살핀다. 공공기관 입찰을 주로 하는 I사는 ‘나라장터’ 등에서 입찰 정보를 수집한다.
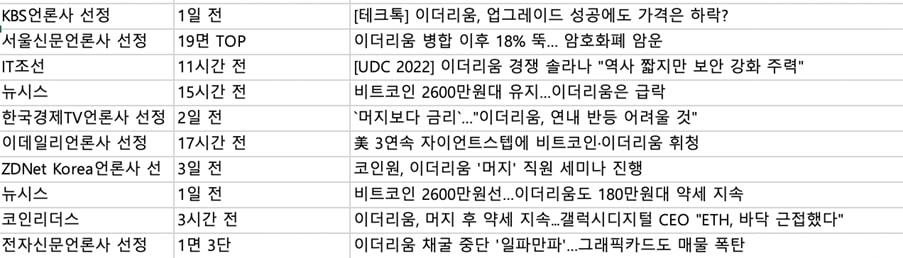
산업 동향을 살피는 데는 뉴스만 한 것이 없다. 블록체인 기업 J사는 ‘블록체인’, ‘이더리움’과 같은 키워드를 이용해 뉴스 검색 결과를 계속 수집한다. 마케팅에서도 뉴스 검색은 중요하다. 보도자료가 얼마나 효과적으로 발행되었는지, 어떤 언론이 우리 회사에 주목하고 있는지가 한눈에 보인다.

마케팅 캠페인의 효과를 측정할 때도 데이터 크롤링이 중요하다. 병원 마케팅 대행사 K사는 검색어 광고를 집행한 후 해당 키워드를 매일 검색해 보고, 이 검색 결과를 크롤링해 엑셀 파일로 저장해둔다. 데이터가 많이 쌓일수록, 그냥 쌓아두기만 한 것과 엑셀로 정량화한 것 사이에 차이가 압도적으로 커진다.
기타: 리뷰 수집, 업체 연락처 수집, 부동산 데이터 정제
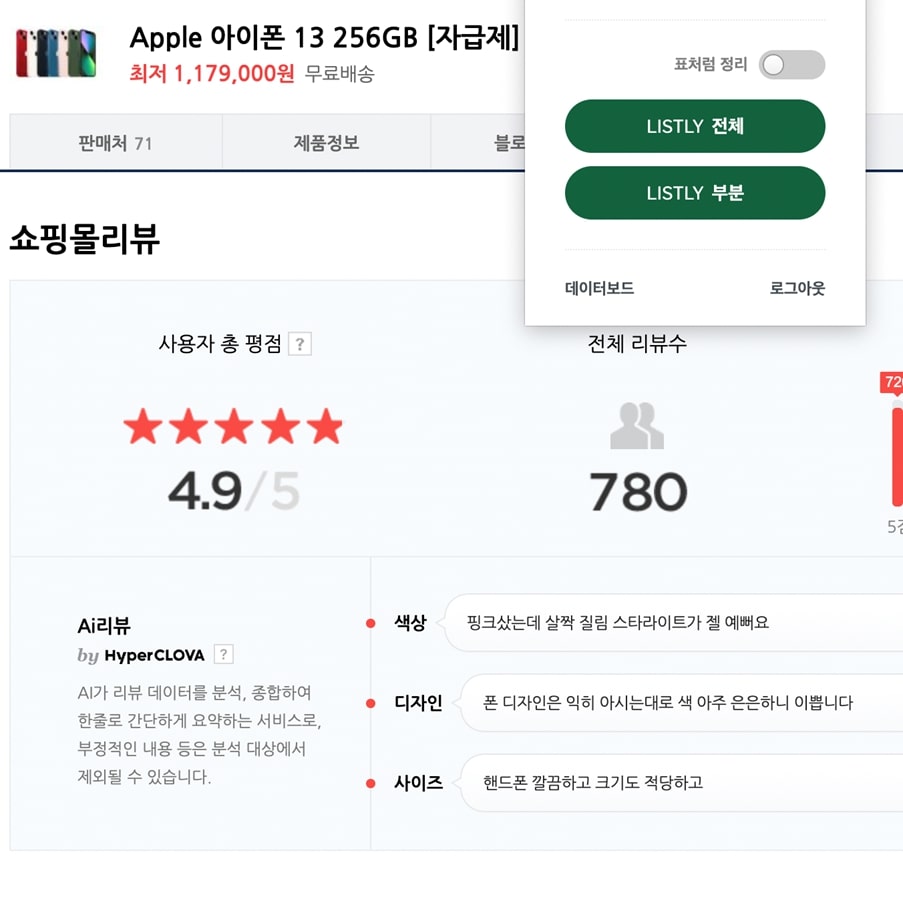
마케팅 에이전시 L사는 상품 리뷰를 수집한다. 정성적인 데이터도 엑셀로 뽑아 두면 한눈에 들어온다. 쇼핑몰별, 평점별로 데이터를 분리할 수도 있다. 또 ‘찍힘’ ‘배송’ 등 특정 키워드를 검색해, 유저들이 어떤 부분에 주로 불만을 제기하는지 알아볼 수 있다.

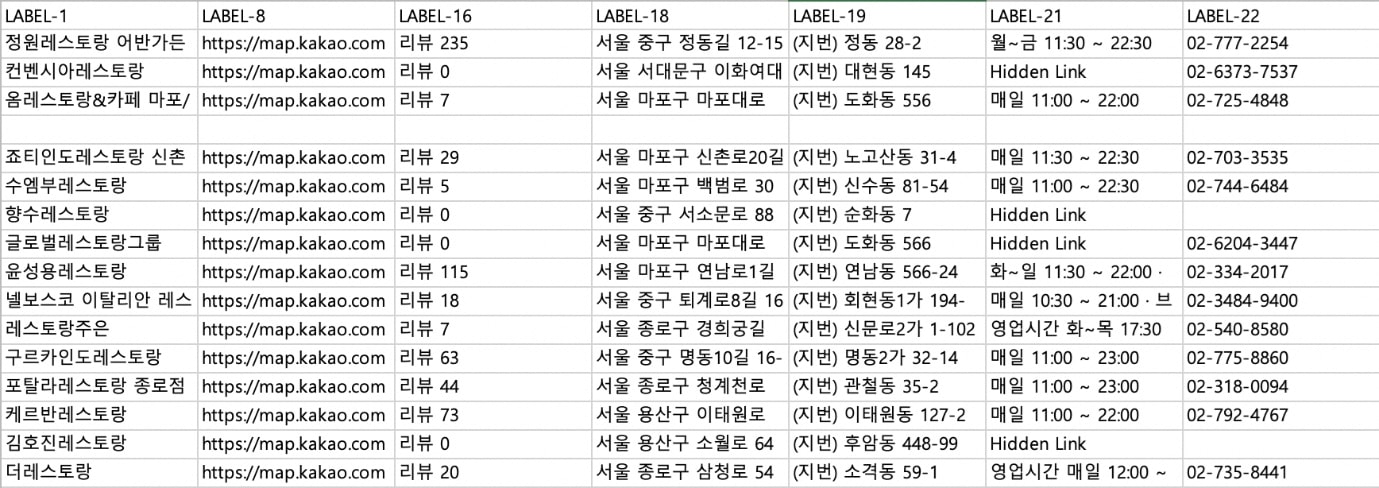
또 한 가지 흥미로운 점이 있다. 무려 13.9%의 데이터가 ‘연락처 수집’이라는 한 가지 작업에 사용되었다는 점이다. M 에이전시는 각종 행사, 협회 홈페이지 등에 공개된 회사 정보와 연락처를 크롤링한다. 지도 앱의 검색 페이지를 크롤링하면, 주변 업소 연락처를 한 번에 수집할 수도 있다.
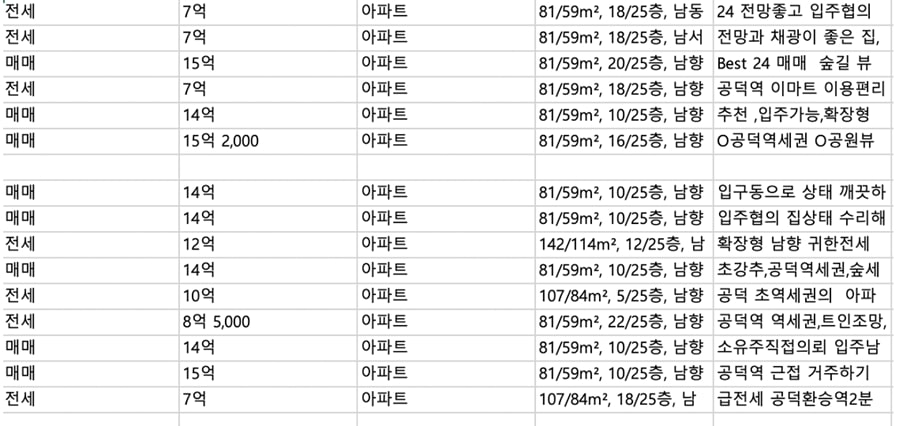
한편, 최근 급격히 데이터 활용이 증가하고 있는 분야가 있다. 5.4%의 데이터가 부동산에서 수집되었다. 구글, 네이버 등에서 제공하는 부동산 포털을 크롤링하면, 특정 지역의 매물을 한눈에 볼 수 있다. 아파트/빌라, 전세/월세, 층수, 임대료 등의 속성에 따라 분류해 다양하게 사용할 수 있다.
데이터, 이젠 선택이 아니라 필수인 시대
데이터는 이제 선택이 아니라 필수다. 하지만 모든 회사가 파이썬을 다루고 데이터 사이언티스트를 채용할 수는 없다. 데이터 수집과 정제는 이들에게도 보통 고달픈 작업이 아니다.
다행인 것은, 자동화 툴을 사용하는 것만으로도 데이터 사이언티스트 부럽지 않게 데이터를 수집하고 정제할 수 있다는 것이다. 설치도 간편하다. 웹 브라우저에 확장 프로그램 하나만 설치하면, 수천, 수만 개의 정보를 수집하는 게 클릭 몇 번으로 가능해진다.
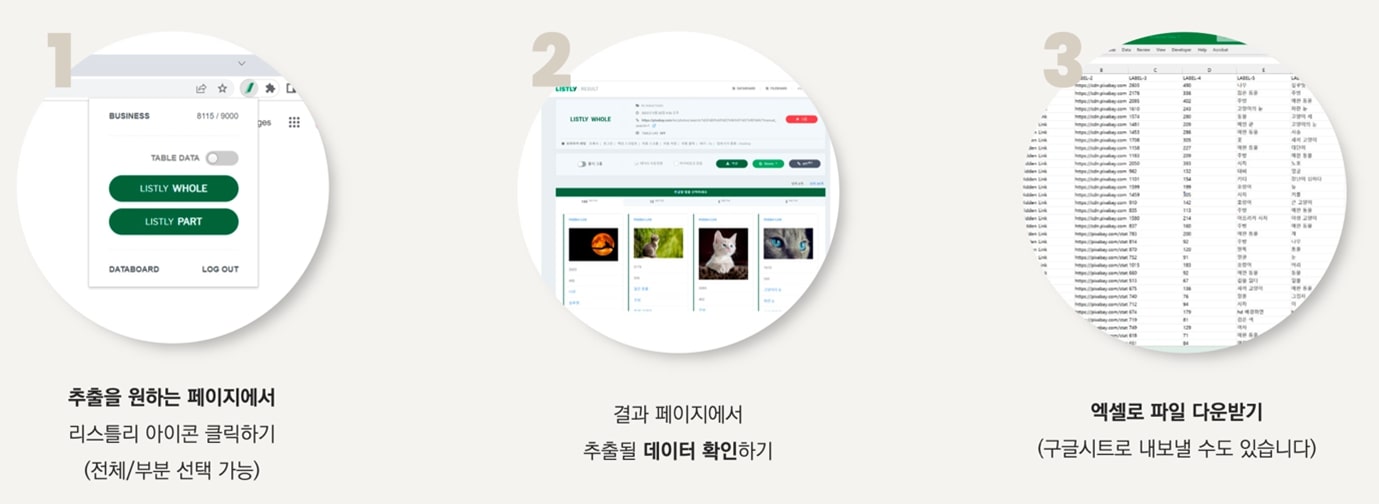
커머스에서는 인기 상품이나 가격을 모니터링하기 위해, 마케터들은 리뷰나 뉴스, SNS 반응을 수집하기 위해, 영업직에서는 연락처를 수집하기 위해, 금융 분야에서는 투자 지표를 수집하기 위해. 필요는 무궁무진하다. 데이터 크롤링은 조직과 서비스를 고도화하기 위해 꼭 필요한 과업이다.

위에서 소개한 사례들을 직접 체험해보고 싶다면 www.listly.io 에서 무료로 사용하실 수 있습니다.
☞ 리스틀리(Listly) 무료로 사용해 보기
표지 이미지 출처