우선순위가 제목에 들어간 영단어책이 인기를 끈 때가 있었다. 그런데 그 우선순위에는 근거가 없었다. 영어권에서 어떤 단어가 어떤 빈도로 쓰이는지 궁금해서 구글의 엔그램 뷰어라는 툴을 통해 웹상의 영어문헌에서 특정 단어가 얼마나 자주 쓰이는지를 분석했다.
2016년 7월 22일 출간과 동시에 예스24 주간 종합베스트셀러 4위, 9위에 오르며 영어교재 시장에서 파란을 일으킨 <빅보카>의 저자 신영준 씨가 출간 직후 연합뉴스와의 인터뷰에서 여타 영어단어장을 향해 던진 당찬 메시지다.
그는 1923년 이전 출간된 2만 4천 권을 디지털화한 프로젝트 ‘구텐베르그’의 8억 단어와 현대 영어 보완을 위한 3억 단어를 합쳐 11억 단어로 우선순위에 기반한 2만 단어를 먼저 뽑아냈다. 이 2만 단어로 2015년 『빅데이터 단어장』을 만들고 기대 이상의 반응을 얻어내자, 이듬해 다시 8천 단어를 추려내 『빅보카』를 세상에 내놓았다. 그는 8천 단어를 추려내는 한편 700만 권에서 추출한 단어의 우선순위가 들어 있는 구글의 엔그램 뷰어로 단어의 우선순위를 재조정했다고 밝혔다.

예문보다 더 강력한 키워드: 최초, 빅데이터 그리고 영어공부
『빅보카』는 예문이 없다는 이유로 비판받았지만 소비자들은 ‘최초로 빅데이터 기반의 진정한 우선순위 단어장’에 더 끌렸고, 결국 주요 4대 서점의 베스트 셀러 1위를 달성하며 10만 부 이상을 팔아 치웠다. 또한 신영준 씨는 예문이 없다는 비판을 잠재우기 위해 같은 해 말 ‘빅보카퀴즈’ 앱을 내놓아 예문과 퀴즈 형식의 학습을 제공하며 위치를 공고히 했다.
하지만 최초도 빅데이터도 아닌, 베껴 출판한 콘텐츠
그러나 2019년 『빅보카』의 전신인 『빅데이터 단어장』이 wiktionary.org의 단어 리스트를 그대로 베껴 출판했다는 의문이 제기되었다. 확인해보니 사실이었다. 사진의 왼쪽은 Wiktionary의 Frequency list이고, 오른쪽이 『빅데이터 단어장』이다. 『빅데이터 단어장』은 랭킹과 단어로만 구성된 간단한 구조를 가지고 있었다.

저자가 표제어로 단어를 묶기 위해 제거한 파란 색깔의 단어를 제외하면 내용과 순서가 정확하게 일치한다. 중반부인 2천 번대 단어들을 비교해 보았지만, 역시 표제어로 묶기 위해 삭제된 단어를 제외하곤 순서와 내용이 정확하게 일치했다. 『빅데이터 단어장』은 Wiktionary의 PG(Project Gutenberg) Frequency list에서 표제어로 묶어낼 단어만 제외하고 그대로 프린트해 판매한 책이었던 것이다.
Wiktionary의 자료들은 Creative Common 정책으로 상업적인 이용도 가능하나 출처를 명시하도록 되어 있고, 변경할 경우 공지를 해야 할 의무가 있다. 그러나 『빅데이터 단어장』과 그를 기반으로 추려진 『빅보카』에는 출처에 대한 표시를 찾을 수 없었다. 저자인 신영준 씨는 『빅보카』의 서문에서 자신이 8억에 3억을 더해 11억 단어의 모수로 통계적으로 분석했다고 했지만, 이는 사실이 아니었다.

“100년 전에 많이 쓰던 단어를 공부하시는군요!”
Wiktionary PG List 단어들은 1923년의 책에서 추출한 단어들인데, 그렇다면 PG List를 제외한 현대어가 얼마나 『빅보카』에 들어 있을까.
PG List 32,000단어와 비교했을 때 『빅보카』의 8천 단어 중 7,744개(97%)가 일치했다. 2006년 TV Script에서 추가된 단어는 120개(1.5%)에 불과했다. miss, manic, braid, afterward, physics와 같은 단어들이었다. 『빅보카』는 여전히 1923년 이전에 주로 쓰였던 단어들이 주력이며, 이를 구글 엔그램 뷰어를 이용해 2008년 기준으로 정렬한 것에 불과했다. 이 때문에 <빅보카>에는 technology, internet, social, laser, television 등과 같은 단어가 없다.
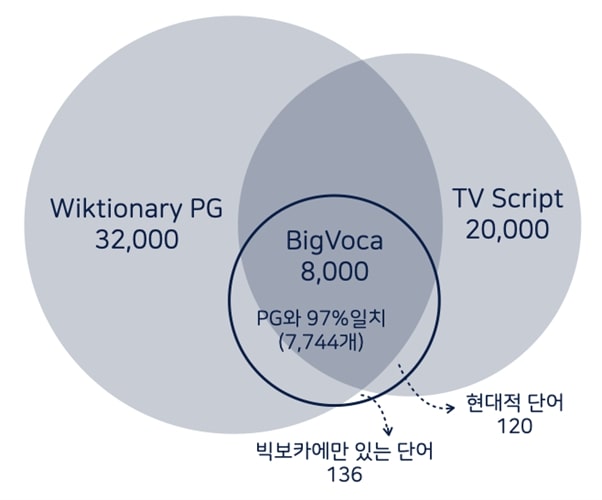
700만 권과 20만 권의 사이, 그리고 차이
저자는 700만 권의 데이터로 우선순위를 검증하였다고 했지만, 700만 권은 엔그램 전체 보유량이고 실제로는 2008년 출간된 20만 권의 데이터로만 순위를 매겼다. 그러니 책에서 선전한 700만 권은 사실보다 과장되었다.
20만 권이라도 신뢰할 만한 데이터라면 문제 되지 않으나, 실제로는 엔그램 버전(2009, 2012, 2019버전)과 연도에 따라 순위 변동이 심해 2008년 데이터만으로는 우선순위를 신뢰하기 어려웠다.
문제점은 또 있다. 아래 그림은 『빅보카』에서 4000위 단어인 senate와 5000위 customize, 5100위 caricature, 5200위 consortium, 5300위 gall, 5400위 gruesome의 여섯 단어를 같은 기간 동안 세 가지 버전으로 조회한 것이다.
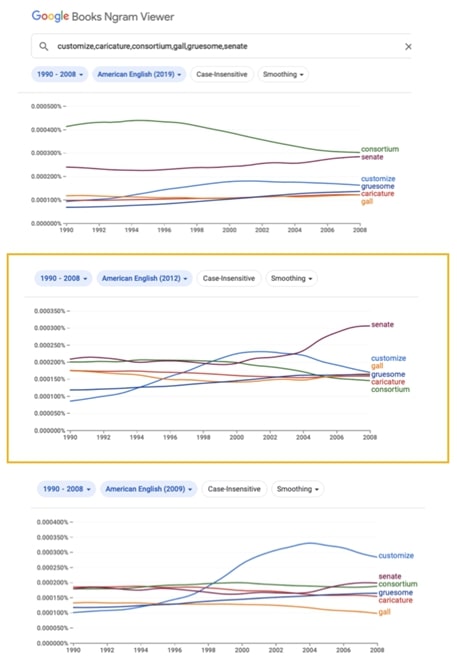
데이터: 잘 분석하면 약, 잘못 분석하면 독
중간의 2012년 버전이 저자가 사용한 버전으로, senate가 모든 단어에 앞서 비중이 높다고 표시되어 있다. 그러나 다른 두 버전의 순위는 제각각이다. 구글 엔그램의 최초 2009버전엔 수백만 권의 책이 담겨있다. 이중 2008년에 출간된 책은 15만 권이 담겨있고, 2012버전엔 20만 권, 2019버전엔 27만 권이 담겨있다. 버전에 따라 단어별 순위 변동이 큰 편이다. 저자는 어느 특정 연도를 기준으로 우선순위를 매기지 말고, 여러 해가 누적된 데이터로 순위를 매겼어야 했다.
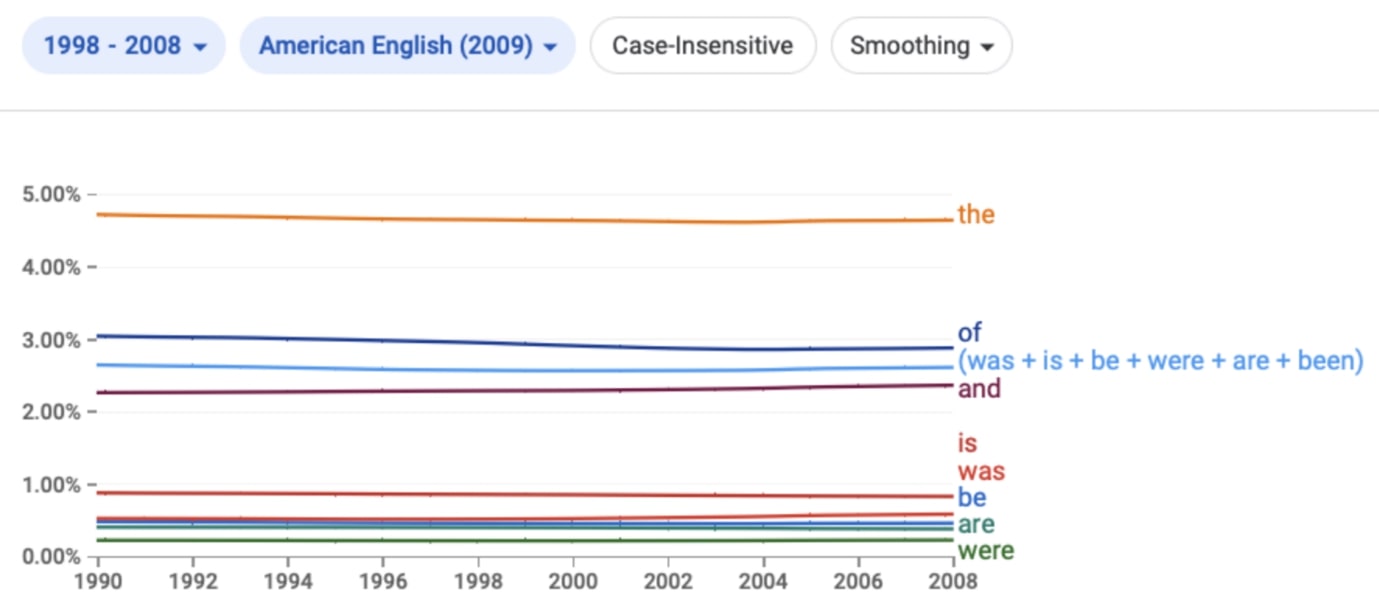
『빅보카』의 표제어 작업 역시 미덥지 못했다. 저자는 is, were, was, been, am를 삭제하고 표제어인 be(15위)로 통합시켰다. 그러면 be의 우선순위는 당연히 삭제한 단어들의 스코어가 모두 합쳐져 조정되어야 하는데, 그대로 삭제하기만 했다. 합산된 be의 우선순위는 1위인 the, 2위인 of에 이어 3위로 올라서야 했지만 『빅보카』에는 15위에 머물러 있고, 이는 삭제된 is보다도 낮은 순위다.
『빅보카』에는 be 외에도 수만 개의 단어들이 표제어로 묶여 조정 없이 삭제되었다. influent와 influence는 모두 등장하지만 influent보다 순위가 높은 evident는 없고 evidence는 나온다. 이 밖에도 west와 south는 나오는데, east와 north는 나오지 않는다. 이처럼 표제어 작업과 우선순위는 모두 신뢰성이 떨어진다.
단어의 뜻풀이는 네이버•다음사전 기준? 저자의 말이 거짓임을 알려주는 데이터들
『빅보카』의 또 다른 논란거리 중 하나는 네이버, 다음 사전의 뜻풀이를 그대로 베껴 썼다는 것이다. 언뜻 ‘뜻풀이는 모든 사전이 비슷하지 않나’고 생각할 수 있지만, 실제로 비교해보면 토씨 하나 틀리지 않고 같은 뜻풀이가 엄청나게 많았다. 출판사와 저자가 네이버(혹은 네이버에 콘텐츠를 공급하는 옥스퍼드 영한사전)의 허락을 받지 않았다면 이는 저작권 침해 문제로 이어질 수 있는 문제다.




또한 이 책은 ‘최근 5개년 수능에서 표제어・관련 어휘를 망라해 한 단어를 제외한 99% 이상 포함률을 보였다’고 한다. 하지만 최고의 ‘물수능’으로 알려진 2015년 수능 영어문제 하나와 비교하자 표제어와 관련 어휘를 제외하더라도 <빅보카>와 일치하지 않는 단어가 쏟아져 나왔다.

총 182단어 중 빅보카에 수록되지 않은 아래 16개 단어가 21회 등장하여 99%가 아닌 88%의 일치율을 보였다.
multiple 3회, psychologist, multitask/multitasking 4회, megahertz, retrospect, deeptive, inherently, misleading, hypothesis, everything, CPU, flip, context, interpret, forth, conceal
또한 아래 단어들 역시 『빅보카』에 수록되지 않았지만, 관련 어휘로 분류하여 포함된 것으로 간주하였다.
ability, quickly, probably, made, choice, expression, alternately, sharing, became, simultaneously, alternating, comparing
“이 예문들, 완전히 신뢰해도 괜찮으시겠습니까?”
문제는 여기에서 그치지 않았다. 『빅보카』 출간 수개월 후 출시된 ‘빅보카퀴즈’ 앱에는 예문이 수록되어 있는데, 여기에도 오류가 많았다. 아래 그림과 같이 ‘교회법’이라는 뜻의 canon과 주식회사 캐논을 구별하지 못하거나, 보통명사 eddy와 사람 이름 Eddy를 구별하지 못하기도 했다.




종합해 보면 『빅보카』는 단어추출과 우선순위 선정, 표제어 작업, 예문, 뜻풀이 등에서 총체적으로 문제를 안고 있는 것으로 보인다. 그럼에도 불구하고 출판사와 저자는 사실과 다른 선전으로 영어 공부에 목마른 수험생과 직장인들에게 책을 판매하여 엄청난 수익을 올렸다. 현재 저자 신영준 씨는 또 다른 영어 공부 서비스인 ‘영어독립’을 베타 테스트 중인 것으로 알려졌다.
신영준 씨와 『완벽한 공부법』을 공동 저술하여 베스트셀러에 오른 고영성 작가는 『빅보카』 출간 이틀 전 ‘빅보카, 감히 ‘세계 최고의 단어장’이라 부르고 싶다!’라는 추천사를 올렸다. 그는 ‘신영준 박사가 모집단 11억을 지프처럼 분석했다’며 추켜세웠다. 이 글은 3천9백 회나 공유되며 『빅보카』를 선전하는 데 톡톡한 역할을 했다.

그러나 그가 말한 ‘조지 킹슬리 지프’ 이야기 역시 『빅데이터 인문학: 진격의 서막』을 그대로 베낀 글이었다.