
조금 거칠지만, 통계학의 쓰임새를 크게 보면 두 가지로 나눌 수 있다.
1) 인간의 지식을 확장하기 위한 것
2) 구체적인 문제에 대해 좋은 의사 결정을 내리기 위한 것
상호보완적인 두 가지 역할
재미있게도 통계학의 대부인 칼 피어슨이 통계학을 만들어낸 동기는 다윈의 진화론을 증명하기 위한 것으로 이것은 1)의 목적에 속한다고 볼 수 있는 반면, 피어슨의 뒤를 이어 통계학의 기초를 정립한 피셔는 농업 회사에서 근무하면서 ‘가장 성능이 좋은 비료를 선택’하기 위한 연구를 하다가 그의 대표 논문을 썼는데 이는 2)의 목적에 더 가깝다.
물론 가장 성능이 좋은 비료가 무엇인지 알아내는 것도 인간 지식의 확장이 아니냐고 반문할 수 있다. ‘A 물질을 97%, B 물질을 2.3%, C 물질을 0.05%, D 물질을 0.003%, …, Z 물질을 0.0017% 섞은 비료가 인디애나 지역에서 옥수수를 키우는 데 가장 적합하다’는 정보는 분명 지식이다. 다만 그 실질적 유용성에 비해 지적인 흥미는 많이 떨어진다.
또, ‘지식을 확장하면 더 좋은 의사결정을 내릴 수 있지 않겠는가’라는 주장 역시 타당하지만, 앞에서 든 피어슨의 예를 보면 진화론을 증명하는 일은 반드시 구체적인 의사 결정이 필요한 상황을 염두에 두지 않더라도 그 자체로 대단히 중요한 지적 가치가 있다. 즉, 두 목적은 상호 배타적인 것은 아니고 대개 통계학을 사용하는 이유에는 둘이 섞여있지만, 상황에 따라 어느 한 쪽에 더 무게가 두어지기도 한다.

인간의 올바른 의사 결정을 돕기 위한 통계학
전통적인 통계학 방법론은 1) 인간 지식 확장의 목적이 중요한 경우를 늘 염두에 두고 있다. 2) 구체적인 문제에 대한 의사 결정이 중요한 상황이라고 해도, 인간은 통계 분석 결과만 바라보고 행동하는 것 보다는 이로부터 얻어진 지식을 비정형적인 다른 지식과 조합했을 때 더 현명한 판단을 내리기 때문이다.
사용한 통계적인 모델이 복잡하면 복잡할수록 그 분석 결과로부터 얻을 수 있는 지식으로서의 가치는 떨어지기 때문에, 통계학 교과서는 가능하면 간단하고 직관적인 해석이 쉬운 모델을 사용하라고 가르친다. 옥수수 수확량이 비료 안에 포함된 칼슘 함량과 비례한다는 것은 흥미로운 지식일 수 있지만, 수확량이 칼슘 함량의 13차 함수라는 사실은 그것이 진실이라고 하더라도 상대적으로 지적인 가치를 찾기 어렵기 때문이다.
또, 통계적인 모델을 사용하기 위해서는 가정들이 필요한데 이 가정들이 실제 현실과 거리가 있으면 분석 결과의 지식으로서의 가치가 의심스러우므로, 모델의 주어진 데이터에 대한 적절성(model fitting)을 확인하는 절차를 가르치는 것 역시 통계학 방법론 교육에서 강조되는 부분이다.
기술 발전의 결과: 이제는 컴퓨터가 의사 결정을 내린다
그런데 현대에 와서 컴퓨터가 발전하면서 새로운 상황들이 나타나고 있다. 컴퓨터가 인간 대신 의사를 결정하고 행동을 취하는 경우들이 생겨나고 있는 것이다.
개인적으로 생각하기에 이 현상이 가장 높은 지적 수준에서 발생하는 예는 이미지 인식(image recognition) – 사진을 보고 사진의 내용이 무엇인지 판단하는 것 – 인 것 같다. 페이스북에 김개똥의 사진을 올리면 컴퓨터 시스템이 자동으로 얼굴이 있는 부분을 찾아 혹시 이것이 김개똥의 사진이 아니냐고 묻는데, 이 경우 컴퓨터가 ‘이 사진에 나온 사람은 누구인지 판단하고 사용자에게 추천’하는 결정을 직접 내리는 것이다.
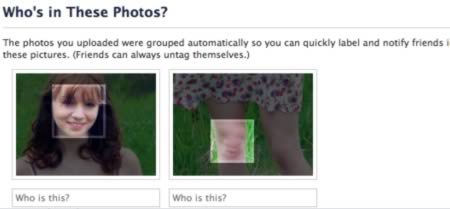
컴퓨터가 일을 잘 하면 페이스북 사용자의 편의를 도모할 수 있지만, 김개똥과 전혀 관련이 없는 이말숙, 장현자 등의 사람을 자꾸 추천하면 사용자의 짜증을 유발하게 되므로 이것은 제법 가치도 위험도 모두 있는 의사 결정 문제이다. 그런데 요즘은 컴퓨터가 나처럼 안면 인식 능력이 부족한 사람보다는 이런 어려운 일을 더 능숙하게 해내므로 제법 대단한 기술적 발전이라고 볼 수 있다.
얼굴 인식의 기반에는 통계학이 있다
흥미로운 것은 컴퓨터가 이러한 의사 결정 문제를 해결하는 데 있어서 통계적인 모델을 사용한다는 점이다. 이것은 이미지 인식처럼 인간조차 정확하게 풀기가 어려운 문제를 컴퓨터가 해결하기 위해서는 컴퓨터가 불확실성을 고려할 수 있어야 하기 때문이다.
예를 들면 아무리 눈썰미가 좋은 사람이라도 김개똥의 사진을 보고서 이것이 김개똥의 사진이라고 100% 확신할 수 있는 경우는 드물기 때문에, 잘 알지도 못하면서 ‘이것이 김개똥이요’라고 지르고 보는 컴퓨터 보다는 확률의 개념을 이용해서 ‘97% 정도 김개똥이라고 확신하지만 2% 정도는 고말똥일 가능성도 있으며 또 1% 정도는 아예 제 3자 인물일 수도 있다’는 것과 같이 자신의 이해가 갖고 있는 불확실성을 기술할 수 있는 컴퓨터가 더 유용한 것이다.
‘99% 확신할 수 없다면, 사용자를 짜증나게 할 수 있는 2%의 가능성을 위해 그냥 아무런 추천도 하지 말자’는 것과 같이 불확실성을 고려한 행동이 가능해지기 때문이다. 통계적 모델들이 만들어진 목적 자체가 바로 데이터가 갖고 있는 불확실성을 다루기 위한 것이기 때문에, 페이스북과 같은 인공지능 시스템들이 통계 모델을 이용하는 것은 자연스러운 현상이다.
의사 결정에 중점을 두며 지식 생산과 멀어지는 컴퓨터의 통계학
그런데 이런 맥락에서는 1) 지식 획득보다는 2) 의사 결정의 목적에 훨씬 큰 비중이 두어지게 된다. 앞서 예로 든 페이스북이라는 서비스의 목적은 사용자들의 편의성을 높이는 것이지 과학의 발전에 있지 않기 때문이다.
그래서 페이스북과 같은 컴퓨터 시스템들이 사용하는 통계적인 모델들은 기존에 인간들이 사용하던 통계 모델들의 미덕인 단순성이나 해석 가능성을 고려해야 할 이유가 별로 없다. 따라서 이러한 시스템들은 전통적인 통계학자라면 눈살을 찌푸릴만큼 변수도 많고 구조도 복잡한 통계적인 모델들을 사용하며, 모델의 적합성도 좀처럼 확인하지 않는다.
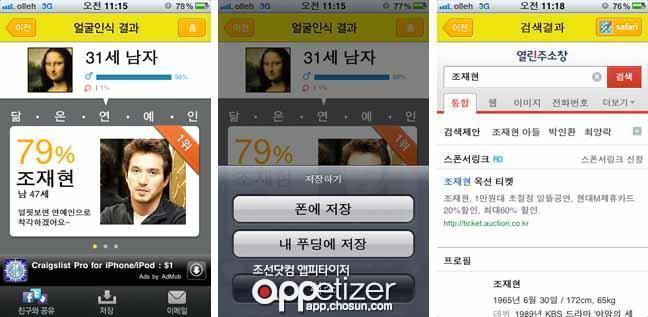
그래서 이러한 모델들을 이용한 결과로부터 인간에게 유용한 지식을 얻어내기는 어렵다. 페이스북은 나보다 이미지 인식을 훌륭하게 수행하지만, 내가 페이스북 시스템을 들여다본다고 해서 이미지 인식에 대해 배울 수 있는 점은 거의 없는 것이다.
인간의 통계학, 컴퓨터의 통계학
결과적으로 인간과 컴퓨터는 모두 통계학을 사용하고 있지만, 시간이 흐름에 따라 둘이 사용하는 통계학 사이에 점점 괴리가 나타나고 있다. 컴퓨터는 차츰 더 많은 영역에서 인간의 의사 결정 능력을 따라잡고 있지만, 컴퓨터가 사용하는 통계적 모델들의 복잡성은 날이 갈수록 올라가며 인간 지식의 확장에 도움이 되지 못하는 것들이 되어가고 있는 것이다. 진화론을 증명하기 위해서 만들어졌던 통계학인데 말이다!
유명 SF 소설 작가인 테드 창(Ted Chiang)의 ‘인간 지식의 진화’라는 단편에서는 인간보다 더 능력이 뛰어난 ‘메타인간’들이 과학 연구를 주도하고, 메타인간들은 인간이 이해할 수 없는 형태로 과학적 지식을 축적하기 때문에, 인간 과학자들의 역할은 새로운 지식을 찾아내는 것이 아니라 메타인간들의 과학적 성과를 인간이 이해할 수 있는 형태로 변환해내는 것이 된 세상을 그린다.
컴퓨터가 사용하는 수백, 수천만개의 변수들이 들어간 통계 모델에 대해 생각하다가, 어쩌면 우리가 그런 세상에 가까워지고 있는 것인지도 모르겠다는 생각이 들어서 이렇게 지루한 글을 썼다…
wandtattooWork clothes for curvy figures