세상에는 세 가지 거짓말이 있다. 거짓말과 새빨간 거짓말, 그리고 통계.
통계는 숫자로 객관적인 자료를 제공하지만, 어떻게 가공하느냐에 따라 사실을 완전히 호도할 수 있다는 점을 경계해야 한다는 의미다.ㅈ

숫자는 거짓말을 한다
지난 10월 3일 개천절을 맞아 보수단체가 계획했던 광화문 집회는 정부의 강력한 봉쇄 정책으로 사실상 무산되었다. 하지만 일부 시위대가 ‘4. 15 부정선거’ 등의 구호를 내세우며 경찰과 충돌하는 일이 벌어지기도 했다.
4.15 부정선거 음모론의 통계를 내세운다. 대표적인 것이 ‘사전투표 음모론’이다. 사전투표에서 더불어민주당의 지지율이 본투표보다 10%p 정도 높게 나왔다는 점을 근거로 든다.
그러나 이는 사전투표자와 본투표자의 투표 성향이 서로 달랐다는 점, 특히 4.15 총선에서 총선 이전부터 ‘사전투표 음모론’이 돌면서 보수층에서 사전투표 기피 성향이 나타났다는 점을 무시한다. 통계로서의 신뢰도가 없는, 말 그대로 음모론에 지나지 않다.
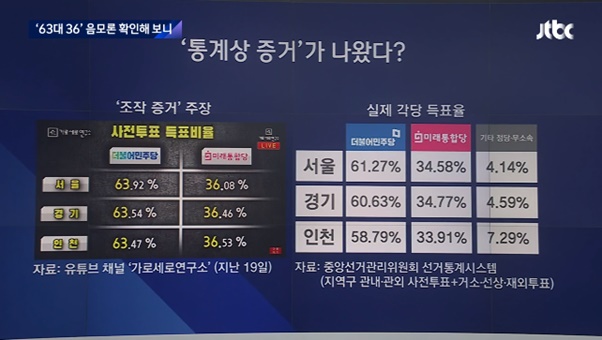
보수 일각은 “숫자는 거짓말을 하지 않는다”고 말하지만, 사실 “숫자는 거짓말을 한다”. 바로 위의 경우에서처럼 말이다. 이는 데이터 시각화와 인포그래픽의 대가, 알베르토 카이로 교수의 최근 저작 제목이기도 하다.

☞ 교보문고 / YES24 / 알라딘 / 인터파크 / 네이버 책
차트도 거짓말을 한다
소셜미디어의 시대, 우리는 손가락으로 스마트폰을 몇 번 터치하는 것만으로 새로운 정보를 계속해서 주입받는다. 이런 시대에 ‘데이터의 시각화’는 매우 강력한 도구다. 일단 ‘눈에 띄고’ 왜인지 ‘더 객관적으로’ 보인다. 차트가 들어가면, 일단 우리는 그 정보를 좀 더 신뢰한다.
그러나 바로 그렇기 때문에, 차트는 우리의 눈을 속이기 쉽다. <숫자는 거짓말을 한다>의 저자 알베르토 카이로 교수는 자신의 전문분야인, 데이터 시각화의 함정들을 보여준다. 차라리 눈에 잘 보이게 엉뚱한 차트는 애교다. 누가 봐도 엉터리라 금새 문제가 드러나기 때문이다.
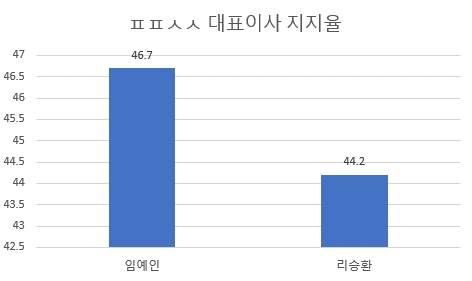
진짜 무서운 건 ‘잘 드러나지 않는’ 왜곡이다. 예를 들어, 기준선이 0에서 시작하지 않는 것만으로도 많은 왜곡을 만들어낼 수 있다. 아래의 그래프는 그 아주 단순한 예이다. 임예인 후보와 리승환 후보의 지지율 격차는 2.5%에 불과하지만, 이 그래프상에서는 그 차이가 세 배는 족히 되어 보인다. 기준선을 0이 아니라 42.5에 두고 0.5 간격으로 그래프를 구성했기 때문이다.
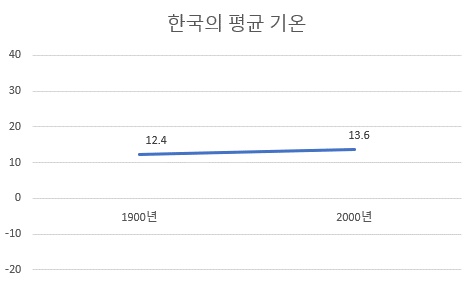
반대로 차이를 적게 보이게 할 수도 있다. 아래의 그래프를 보면, 한국의 평균 기온은 100년간 그리 크게 변한 것 같지 않아 보인다. 하지만, 기후변화는 단 1도 차이로도 치명적인 결과를 초래할 수 있다. 따라서 차트는 저렇게 넓은 범위에서 그려져서는 안 된다.
이건 차트가 보여주는 ‘대표적인 거짓말’ 들이다. 대놓고 숫자가 틀리거나 그래프를 엉터리로 그리는 경우도 있지만, 굳이 그럴 필요 없이 기준점만 조금만 손을 봐도 본질 자체가 변해버린다.
데이터 시각화도 거짓말을 한다
<숫자는 거짓말을 한다>는 우리가 흔히 보는 ‘그래프의 왜곡’ 뿐 아니라, 여러가지 흥미로운 ‘시각화’의 함정들을 보여준다. 개중 가장 흥미로웠던 사례 중 하나는 바로 태풍 경로다.
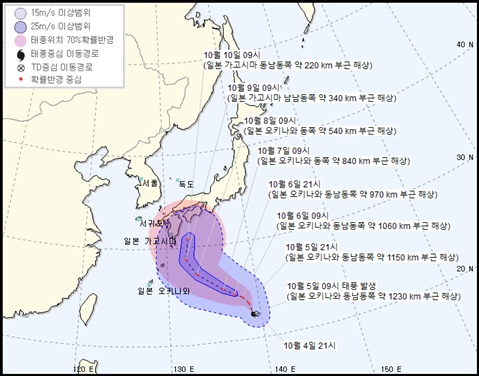
우리는 저 원뿔 모양을 태풍의 ‘크기’를 보여주는 것으로 받아들인다. 처음엔 작았던 태풍이 가면 갈수록 거대한 크기로 발전하는 것이라고 말이다. 하지만 그렇지 않다. 원뿔은 그저 태풍 중심의 ‘이동 경로’와 ‘확률 반경’을 보여주고 있을 뿐이다. 커지는 게 아니라 서쪽으로도 동쪽으로도 갈 수 있다는 것. 그나마 30% 확률로 태풍의 중심이 저 영역 바깥으로 나가 버릴 수도 있다.
시각 정보를 보는 순간 우리는 어떤 선입견 같은 걸 품게 된다. 예를 들어 저 태풍 이동 경로 범위를 자연히 ‘면적’이라 생각하듯 말이다. 때문에 <숫자는 거짓말을 한다>의 저자는 항상 차트를 의심하며 보는 훈련이 필요하다고 한다. 너무나 많은 이들이 우리를 속이고 있으니 말이다.

☞ 교보문고 / YES24 / 알라딘 / 인터파크 / 네이버 책
숫자가 있다고 해서, 그게 무조건 진실은 아니다
함정은 시각화에서만 일어나지 않는다. 데이터 그 자체에서도 발생한다. 심지어 데이터 자체는 사실이더라도, 얼마든지 맥락을 왜곡하여 사람들을 속일 수 있다. 예로 최근 코로나19는 그 영향력 만큼이나, 수많은 엉터리 해석들을 낳고 있다.
그 중 하나의 음모론을 보자. 한국에서 코로나19로 사망한 사람의 수는 10월 5일 기준 422명, 그리고 한국에서 연간 독감으로 사망하는 사람의 숫자는 2천 명이 넘는다. 이를 근거로 코로나19는 사실 그렇게 위험한 질병이 아님에도 (사실 독감보다도 덜 위험한데도!) 정부가 반대파의 입을 막고 탄압하기 위해 일부러 상황을 과장하고 있다고 주장한다.

<숫자는 거짓말을 한다>의 저자 알베르토 카이로 교수는, 이런 데이터의 함정을 천연두 백신의 예로 설명한다. 천연두에 걸려 사망한 아동이 40명, 천연두 백신 때문에 사망한 아동이 90명이라고 가정하자. 이 숫자만 보면 천연두보다 천연두 백신이 오히려 더 위험하며, 따라서 천연두 백신을 접종해선 안 된다는 결론에 힘을 실어주는 것처럼 보인다.
하지만 이건 천연두 백신을 접종함으로써 천연두의 맹위가 사그러들었기 때문에 생긴 결과일 뿐이다. 코로나 방역 음모론도 마찬가지다. 코로나 사망자 수를 400명대 수준에서 막을 수 있는 것은 정부가 방역을 매우 강력하게 밀어붙이고 있기 때문이다. 코로나19 방역에 상대적으로 실패한 미국의 경우, 코로나19로 인한 사망자 수는 무려 21만에 달한다.

‘사망자 수가 적음에도 불구하고 과도하게 방역을 하고 있다’는 게 아니라, ‘과도할 정도로 방역을 하기 때문에 사망자 수가 적다’는 쪽이 정답인 것이다.
통계는 진실이 아닌 추정을 보여줄 뿐이다
우리가 흔히 하는 또 한 가지 오해 중 하나는, 통계가 ‘확고한 진실을 보여준다’는 기대다. 하지만 통계가 줄 수 있는 건 불완전한 추정 뿐이다. 그건 언제든 수정되고 변할 수 있는 것이다. 예로 여론조사를 보자.
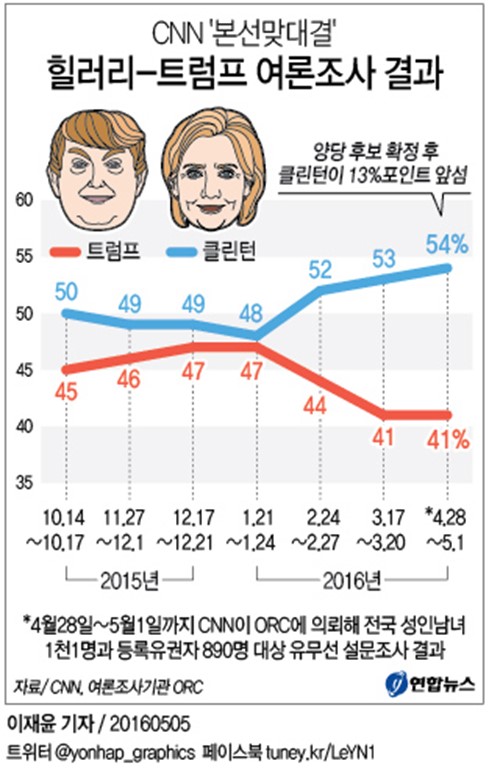
여론조사는 수없이 뒤집힌다. 하지만 이는 여론조사가 ‘틀렸기’ 때문은 아니다. 오히려 여론조사의 한계에 가깝다. 여론조사는 오차범위가 있고 그 안에서는 얼마든지 결과가 뒤바뀔 수 있다. 또 선거 당일 사람들의 마음도 바뀔 수 있고, 생각과 다른 답을 했을 수도 있다.
즉 여론조사는 통계가 ‘믿을 수 없다’는 걸 뜻하지는 않는다. ‘불완전한’ 추정인 동시에, 현재 가지고 있는 데이터에서 얻어낼 수 있는 ‘최선의’ 추정이기도 하다. 이런 통계와 데이터에 대한 기반 지식이 없으면, 쉬이 음모론으로 빠질 수 있다.

☞ 교보문고 / YES24 / 알라딘 / 인터파크 / 네이버 책
숫자와 차트를 제대로 분석하고 이해하기 위한 책
저자의 핵심적인 메시지는 이것이다. 숫자와 차트는 우리를 똑똑하게 만들고 유익한 대화를 할 수 있도록 돕지만, 그러려면 차트를 제대로 읽어야 한다. 게시자와 출처를 확인하고, 의구심이 드는 데이터가 있다면 주변의 조언을 구하기도 해야 한다. 다양한 미디어를 접하고 정파성이 지나친 미디어를 피해야 한다.
위에서 얘기한 바와 같이, 누군가는 코로나19로 인한 사망자가 400여 명에 지나지 않는다는 점을 들어 한국의 코로나 방역이 과도하다고 주장할 수도 있다. 이건 데이터를 명백히 ‘잘못 읽은’ 것이다. 이렇게 잘못 읽은 데이터는 상황을 겉잡을 수 없이 악화시킬 수도 있다.

숫자와 차트는 ‘완벽하게 객관적인’ 그 무엇이 아니라, 끊임없이 파고듦으로써 ‘현재 시점에서 최선의 이해를 제공하는’ 한 도구이다. 이것은 알베르토 카이로 교수가 ‘데이터와 차트에 속지 않는 법’을 우리에게 강의하면서 던지는 가장 핵심적인 메시지이기도 하다.
우리는 ‘진짜’ 데이터를 ‘제대로’ 읽어내고, 거기에서 또 새로운 질문을 계속해서 던져야 한다.
