
지난번 글 「넘치는 마케팅 데이터, 잘 쓰고 계신가요?」에서는 마케팅 데이터를 분석하는 목적에 대해 알아봤습니다. 미국의 유명 마케팅 IT 자문 회사인 ‘가트너(Gartner)’는 마케팅 데이터 분석 목적에 대해 크게 6가지가 있다고 했었죠.
- 측정
- 최적화
- 실험
- 세그먼트
- 모델링/예측
- 스토리텔링
각 단계의 정의와 예시 상황을 설명하면서 특히 마케팅 데이터 분석의 목적 중 현상의 원인과 결과를 이해하고 인사이트를 공유하는 측정과 스토리텔링에 대해 강조했습니다. ‘측정’과 ‘스토리텔링’이라는 데이터 분석의 목적을 달성하기 위해서는 시각화의 역할이 굉장히 중요했죠.
그렇다면 한 단계 더 나아가서, 과연 잘 만든 시각화, 좋은 데이터 스토리텔링은 무엇일까요? 이번 칼럼에서는 실제 마케팅 데이터를 활용하여 좋은 시각화 차트를 만드는 법과 데이터 스토리텔링에 대해 알아보도록 하겠습니다.
1. 시각화, 그 존재의 이유
데이터를 시각화하면 숫자만으로는 파악하기 힘든 부분들이 파악됩니다. 게다가 여러 종류의 데이터가 모여있으면 다루기가 힘들고, 효과적으로 보여주기도 까다롭죠. 아래 간단한 네이버, 페이스북의 노출 수 현황을 표현한 테이블과 차트를 비교해볼까요?
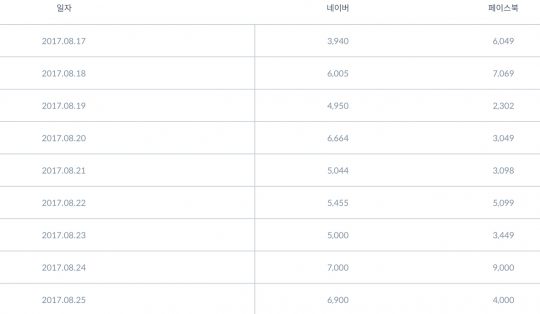
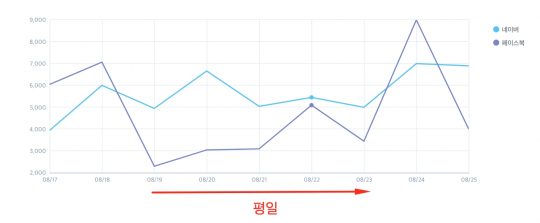
우리는 숫자가 나열된 테이블이 아닌 라인 차트를 통해 다음 이야기를 뽑아낼 수 있을 것입니다.
- 네이버 노출 수는 5000대 초반을 꾸준히 유지하는 반면, 페이스북의 등락은 심한 편이다.
- 8월 24일 네이버, 페이스북 모두 광고 노출이 급증했다.
- 주말에는 네이버보다 페이스북 노출 수가 증가하여 좋은 성과를 보이지만, 네이버는 평일에 더 나은 성과를 보인다. 목요일-금요일은 두 채널 모두 노출 수가 감소한다.
표로 나열된 데이터에서는 찾지 못했던 패턴들이 시각화했더니 나타납니다. 그리고 이게 바로 데이터가 얘기해주는 인사이트가 됩니다.
이처럼 시각화를 사용할 경우 데이터 안의 메시지를 전달하는 측과 받는 측 사이에 존재하는 지식의 격차를 좁히기 쉽기 때문에 매우 효율적인 수단입니다.
위 사례는 간단한 데이터 예시였고, 실제 온라인 마케터들은 특히나 여러 채널의 데이터와 고객의 각 단계별 행동 데이터를 취합해서 파악해야 하기 때문에 조금 더 구체적인 시각화 방법론이 필요합니다.
2. 목적에 맞는 차트, 업무를 줄여주는 필살기
제대로 된 시각화 분석을 위해서는 그만큼 데이터의 종류에 따라 목적에 맞는 차트 유형을 잘 사용하는 것이 중요합니다. 그런데 이 차트 유형이라는 것이 생각보다 다양합니다. 일반적으로 알려진 막대나 선, 파이 차트 외에도 트리맵, 버블, 평행좌표, 지도 시각화, 산점도 등 생각보다 다양한 차트 유형이 있습니다.
그렇다면 이 중에서 어떤 차트를 어떤 상황에 써야 맞는 걸까요? ‘목적에 맞는 차트 선택법’이 있다는 점, 알고 계셨나요? 미국 the Catholic University of America의 교수인 Abela이 슬라이드 레이아웃 백과사전이라는 자신의 웹사이트에 소개한 내용입니다.
우선 데이터를 봐야 하는 목적에 따라 비교, 구성, 분포와 관계로 차트의 종류를 구분할 수 있습니다. 각각은 어떻게 다른지 간단한 정의를 통해 구분해보도록 할까요?
1) 비교
- 서로 다른 집단(카테고리) 간의 수치적 차이를 구분하는 것
- 기준이 되는 값과 분석 대상의 값을 놓고 그 차이를 측정하는 과정
- 예) 페이스북 노출 수와 인스타그램 노출 수의 차이를 측정한다, 1월 매출과 3월 매출의 변동을 측정한다.
2) 구성 (비율, 비중)
- 한 집단을 이루는 개별 아이템들의 수치적 차이를 구분하는 것
- 데이터의 특성에 따라 절댓값으로 볼 것이냐, 상대값으로 볼 것이냐 차이가 있음
- 예) 페이스북 전체 광고 중 동영상, 배너, 콘텐츠 광고의 노출 수를 측정한다.
3) 분포
- 개별 아이템들이 수치적으로 어떤 포지션(최대, 최소, 전체 분포)을 이루고 있는가를 판단하는 것
- 이때 시계열의 구분이 아니라 분류, 세부 분류에 따라 구분해야 함
- 예) 전체 광고를 통한 매출이 네이버, 페이스북, 인스타그램 등의 여러 채널에서 골고루 유입되고 있는가, 어느 한 채널에 의존적으로 유입되고 있는가를 확인한다.
4) 관계
- 데이터를 구성하는 특성 간의 관련성이 있는가를 확인하는 과정
- 상관관계, 인과관계 등 데이터 패턴의 관련성을 측정하는 단계
- 예) 매체의 광고 비용을 높이는 것보다 노출 수를 높이는 것이 광고 전환이 증가하는데 관련성이 있다.
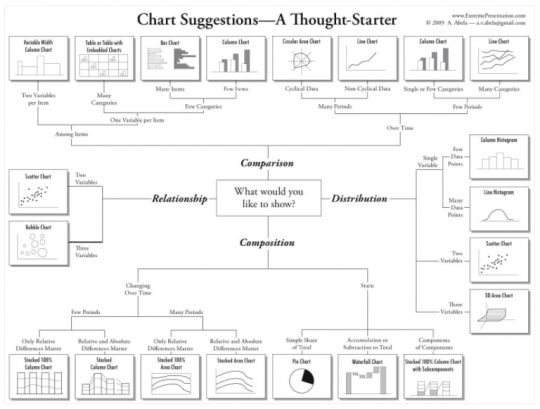
비교와 구성의 경우, 시간의 흐름에 따른 변화를 추가로 살펴본다는 목적에 의해 사용하는 차트가 다를 수 있습니다. 또한, 분포와 관계의 경우 사용하는 차트가 비슷합니다. 두 가지 이상의 지표 결과가 분포하는 내역을 보면, 자연스럽게 관계가 있는지를 같이 볼 수 있기 때문입니다.
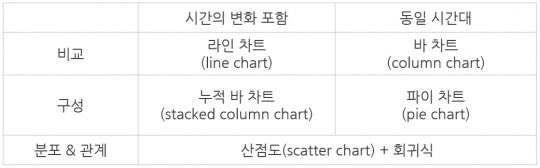
위 4가지 목적은 데이터 시각화의 기본 목적이 되며, 데이터 스토리텔링의 핵심 기준이 됩니다. 여러분이 자주 참고하는 보고서를 보면 아시겠지만, 잘 만든 보고서일수록 사용하는 시각화의 종류가 다양하고 화려하지 않습니다. 전달하고자 하는 정보에 대하여 그 목적이 무엇이냐에 따라 기본적이고 심플한 차트를 사용할수록 수용자의 이해와 파악이 직관적으로 이뤄질 수 있습니다.
3. 마케팅 데이터로 보는 차트 인사이트
1) 비교 인사이트
차트를 통해 얻을 수 있는 첫 번째 인사이트는 바로 ‘비교’입니다. 시각화가 데이터 분석에 효율적인 이유는 데이터의 크기를 시각적인 패턴을 통해 구분할 수 있기 때문입니다. 단순히 하나의 데이터만으로는 그 값이 좋은 것인지 나쁜 것인지 판단할 수 없습니다. 이처럼 비교에서 데이터 스토리텔링이 시작된다고 해도 과언이 아닙니다.
예를 들어 혹시 내가 일주일 동안 집행한 광고가 일별로 어떤 성과 변화가 있는지 알아보고 싶으신가요? 그렇다면 라인 차트를 선택할 수 있습니다. 라인 차트에서 갑자기 수치가 급등한 차트가 있는지 확인했습니다. 차트의 기울기가 갑자기 급등했다면, 해당 광고에 어떤 일이 있었구나, 짐작할 수 있겠죠.
그렇다면 이 키워드에 무슨 일이 있었던 것일까요? 1차적으로는 부정클릭이 있었는지 확인해볼 수 있습니다. 확인 결과 부정클릭이 아닌 순수성과의 비율이 80% 이상이라면, 해당 키워드가 당시에 전환을 많이 발생시키는 다른 특성이 있을 수 있습니다. 그 관련성을 파악하여 하나의 방법론으로 만든다면 유사한 성과를 다시 한번 만들어 낼 수 있을 겁니다.
또한 그에 따른 매출도 어떻게 발생하게 되는지 라인 차트를 겹쳐서 시각적으로 패턴을 확인할 수 있습니다. 해당 키워드의 성과가 좋을 때 매출도 동시에 상승한다면 해당 키워드는 매출에 직접적인 영향을 미치는 광고 수단으로 인지하고 이를 전략적으로 관리하는 결정이 이뤄지겠죠.
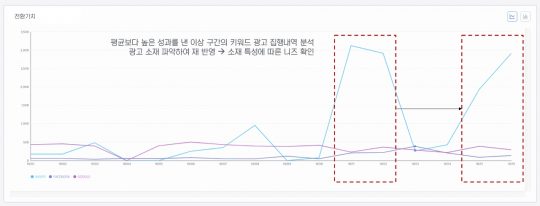
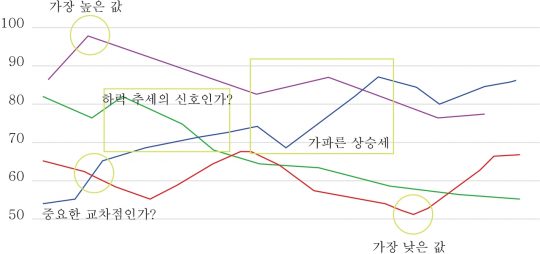
이처럼 라인 차트를 활용하게 되면, 시계열의 변화에 따른 데이터의 변동에 대해 파악할 수 있습니다. 라인 차트의 최댓값, 최솟값의 시점을 확인하여 값에 영향을 미치는 변수를 확인할 수 있고, 가파른 기울기를 보이는 구간, 라인이 교차하는 구간 등이 있을 경우, 변화의 원인에 대해 파악하면 의도적으로 그 원인을 조성하여 원하는 상황을 만들 수도 있고, 원하지 않은 상황이 나타나지 않도록 미리 대응할 수 있을 것입니다.
역으로 현재 보이는 데이터의 시계열 변화를 보고 향후 어떤 방향으로 데이터가 변화할 것인지에 대한 예측도 가능합니다. 굳이 통계분석을 하지 않아도 라인 차트가 그리는 패턴만으로도 향후 값의 수준에 대해 짐작할 수 있지요. (물론 시각화를 통해 패턴만 확인할 수 있을 뿐, 직접적인 수치를 추출하기 위해서는 회귀분석 등의 통계 분석이 필요합니다.)
2) 구성 인사이트
두 번째는 구성을 통해 확인하는 인사이트입니다. 혹시 어떤 광고가, 어떤 채널이 전체 대비 효과를 가지고 왔는지가 궁금하지 않으신가요?
단순하게 지난주 회원가입 비중이 가장 높은 캠페인이 궁금하다면, 파이 차트가 적절합니다. 이번 주 유입 비중이 어떻게 달라졌는지 변화가 궁금하다면, 누적 바 차트(stacked column chart)를 활용할 수 있습니다.
대부분의 광고, 로그 솔루션에서는 이런 ‘구성’에 대한 차트를 볼 수 있습니다.
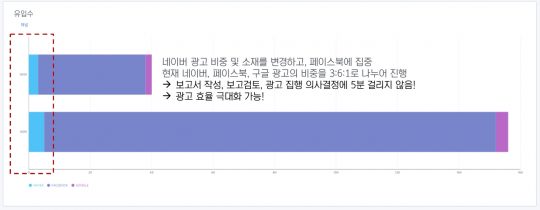
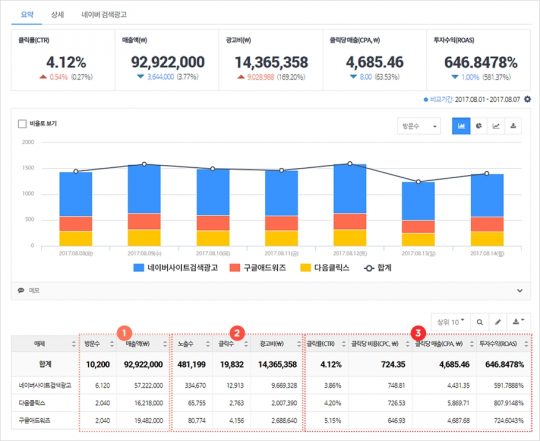
위 화면은 로그 분석 솔루션인 Acecounter에서 제공하는 차트의 모습입니다. 네이버 사이트 검색 광고와 다음클릭스, 구글 애드워즈 등 3가지 매체로부터 발생한 성과데이터를 확인할 수 있습니다. 방문 수를 기준으로 보면, 가장 많은 방문 수는 네이버검색광고이며, 60%가량을 차지하고 있는 것을 확인할 수 있습니다.
반면, 구글 애드워즈는 비중이 줄어가는 걸 확인해볼 수 있습니다. 만약 이 추세가 계속된다면, 효율적이지 않은 구글 애드워즈의 광고를 중지하겠다고 결론 내려볼 수 있겠죠. 물론 이런 결론을 위해서는 광고의 예산, 광고의 성격 등이 유사해야 합니다. 서로 다른 특성을 가진 집단 간의 구성 변화를 보고 판단을 내리는 것은 다양한 변수가 있기 때문에 성급할 수 있습니다. 위 결과를 통해 각 채널의 광고 조건이 균일했는지 파악해보고, 다른 변수는 없었는지 파악하는 추가 조사가 필요합니다.
이처럼 한 집단을 이루는 아이템들의 구성과 그 시계열 변화를 확인하면 어떤 곳에 집중할 수 있을지 우선순위를 판단할 수 있습니다.
3) 분포와 관계 인사이트
세 번째는 분포와 관계입니다. 관계를 살펴보는 방법은 두 가지가 있는데, 두 지표가 어떤 연관 관계가 있는지를 살펴볼 수도 있고, 혹은 한 지표가 다른 지표의 결과에 영향을 미치는 관계(회귀분석)에 의해 결정이 됩니다.
지난번 칼럼에 대체 ‘상관성이 있다’는 게 무슨 일인지에 대해 자세한 설명해 드렸었죠. 정작 원리는 알았지만, 막상 어떻게 활용해야 할지 감이 안 옵니다.
광고분석 솔루션 매직테이블의 ‘채널 간 지표 비교’ 분석기능을 사용하여 예를 들어볼게요. 여러분이 쇼핑몰 운영자라고 생각해봅시다. 지난주에 갑자기 회원가입자 수가 늘어났습니다. 현재 쇼핑몰 유입을 위해 내가 운영하는 매체는 네이버, 페이스북, 구글 gdn, 인스타그램입니다. 각 매체의 클릭율과 회원가입자 수의 현황을 차트에 나란히 그려보겠습니다.
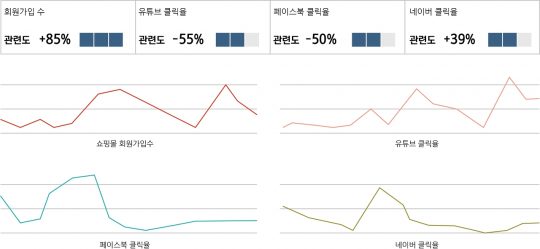
확인 결과, 유투브의 클릭율과 회원가입의 연관 관계가 높았습니다. 자세히 보니, 특정 날짜에 youtube의 증가 폭과 회원가입수의 패턴이 비슷한 것도 확인이 되네요. 이를 통해 쇼핑몰 운영자는 회원가입을 더 늘리기 위해 youtube의 광고를 연장, 집행 예산을 더 상향해보기로 결정했습니다.
이처럼 여러 데이터와 내가 보고자 하는 특정 데이터의 결괏값 간에 어떤 관계가 있는지 알게 되면, 원하는 결괏값을 얻기 위해 하나의 변수로서 해당 데이터를 높이거나 줄이는 방법을 실행하여 광고 전략을 세울 수 있게 됩니다.
즉, 데이터 스토리텔링은 데이터의 패턴을 비교/구성/분포/관계의 관점으로 바라보고, 다음 행동을 위한 가설을 만드는 작업이라고 이해하면 됩니다. 데이터가 얘기하는 인사이트를 발견하고, 이를 더 높이는 방향 또는 줄이는 방향을 위한 전략을 만들어 실행하면 됩니다.
데이터 스토리텔링은 ‘데이터를 어떻게 활용할 것이냐’에서 부터!
이런 활용 사례와 시각화 종류를 공부하며 우리가 생각해봐야 할 지점은 바로 데이터를 ‘어떻게’ 활용할 것이냐에 대한 관점이 필요하다는 것입니다. 여기에 데이터를 읽어 내는 능력, ‘데이터 리터러시’에 대한 배경지식이 필요합니다.
시각화를 할 수 있는 방법은 점점 쉬워지고 있고, 쓸 수 있는 시각화의 종류, 시각화 솔루션도 다양합니다. 실시간으로 쏟아지고 방대한 양의 데이터를 보유하고 있다는 것이 데이터를 잘 활용한다는 것이 아니라는 것을 마케터 모두 잘 알고 계시겠죠.
마케터가 데이터를 잘 활용하기 위해서는 기술적으로 다루는 것부터 숨겨진 인사이트를 도출해 내는 과정 전반에 데이터 리터러시 역량이 필요합니다.

데이터 활용에서도 어떤 툴을 얼마나 잘 다루느냐의 문제보다도 데이터로 문제를 바라보고, 데이터에서 의미 맥락을 발견할 줄 아는 관점과 능력이 중요함을 강조하고 싶습니다.
다음번에는 실전에 바로 활용할 수 있는 마케팅 통계분석 편으로 돌아오겠습니다. 데이터로 최적의 상품 유형을 추출해 내는 방법, 기간끼리 얼마나 성과가 좋았는지, 이상치가 있는지 등등 ‘숫자’의 의미를 이해하고 이야기로 해석해 낼 방법을 알려드릴게요.

원문: 매직테이블의 브런치